
Knowledge over massive data is the new gold. Any medium-sized company can easily hold more than hundreds of thousands of documents in various systems across Wiki, Google Drive, or Dropbox, and it’s crucial information crossing these systems that must be accessed and understood quickly to make informed decisions. Any educational institution needs to continuously update its curriculum with the latest knowledge by relying on a broad spectrum of sources, including newly published papers, scholarly books, and articles from research databases, while also utilizing platforms like Google Scholar to immediately access new research upon publication.
Retrieval-Augmented Generation (RAG) systems can revolutionize how these organizations operate by integrating Large Language Models (LLMs) with their vast, ever-changing data troves to produce relevant deep insights and high-quality actionable outputs. However, the true challenge and the real impact of RAG systems lies in the ability to efficiently ingest, process, synchronize, and retrieve information at large scale. Without robust solutions to solve the scalability challenges, even the most advanced RAG systems struggle to deliver their full potential.
We are glad to share that our no-code/low-code RAG-as-a-Service Platform (https://cloud.epsilla.com) now offers a great solution to scale your knowledge discovery and harvest journey.
The Big Challenge
Feeding a small amount of data to a RAG system is easy. Famous LLM application frameworks like LangChain and LlamaIndex both provide rich ecosystems of data loaders that can easily load data from a diversified type of data sources. The complexity increases exponentially when scaling these systems to meet production-level demands, especially when dealing with more than hundreds of thousands of data files from diverse sources.
- Data Ingestion at Scale: Efficiently managing the ingestion of massive datasets from various sources, such as Notion, Google Drive, and other content repositories, is crucial. The challenge lies in optimizing the speed and cost of data ingestion.
- Efficient Data Embedding: Transforming extensive data into vector formats for efficient retrieval involves significant computational resources. The continuous generation and updating of embeddings to ensure data freshness are pivotal, as outdated vectors can significantly reduce the RAG system’s effectiveness.
- Data Synchronization: Ensuring timely synchronization from various data sources at scale is a major challenge. Thinking about new files being added to a Google drive folder, and old files being deleted. How to make the vector database keep updated? Maintaining synchronization without data loss or duplication is crucial to the system’s reliability and performance.
- System Robustness and Monitoring: Robust monitoring and operational resilience are essential for a scalable RAG system. This encompasses intuitive progress reporting, comprehensive logging, efficient alert systems, and mechanisms for handling operational failures gracefully. These features are vital to maintaining continuous service availability and high performance as the system scales.
Our Solution
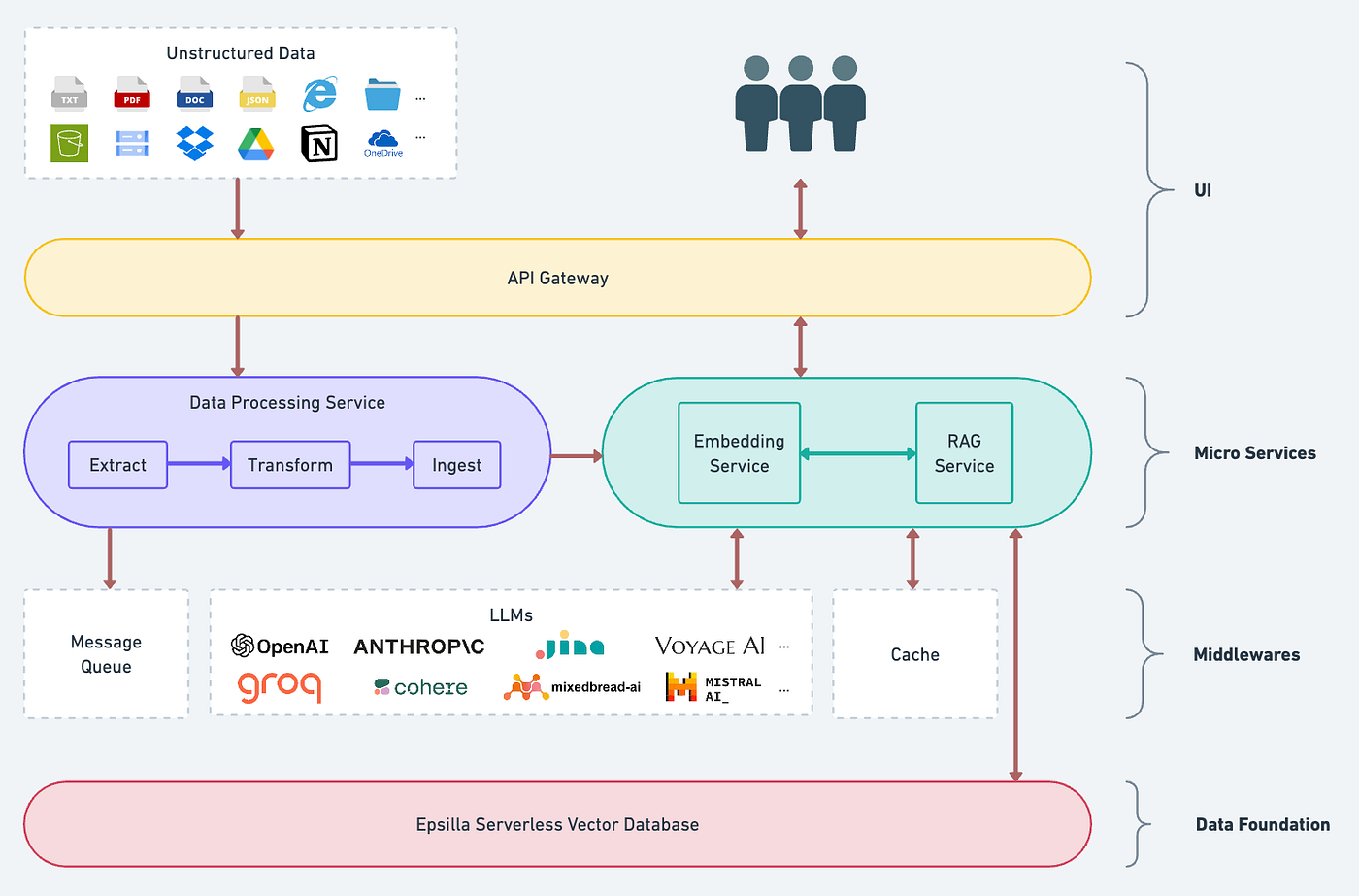
Epsilla proposes Large Scale Smart ETL for Unstructured Data in RAG Systems. Our approach optimizes large scale data synchronization and processing, significantly enhancing the stability and observability of the overall system. This architectural strategy tackles the challenges of scalability, and improves system performance and data accuracy in demanding production environments.
User Interface Epsilla’s User Interface is intentionally designed to support a comprehensive range of data source configurations, allowing customers to seamlessly upload files from local systems, configure website URLs, or set up object buckets and network storage with periodic data synchronization. This flexibility is enhanced by real-time progress updates available through the Epsilla Cloud platform. Complementing the UI, our API Gateway offers a programmatic interface. It not only handles massive data volumes and high user concurrency but also integrates advanced features such as authentication, routing, dispatch, and dynamic scaling. These capabilities are meticulously monitored via Grafana Cloud, tracking API performance, operational metrics, latency, and error rates to ensure high availability and system integrity.
Micro Service Layer The Micro Service Layer forms the core of our data processing and ETL-RAG workflow:
- Data Processing Service: Built on Celery with distributed message queues, this service scales workers dynamically to manage extensive datasets in Extraction, Transform and Ingest, enabling parallel data processing for multiple users simultaneously.
- Embedding Service: Operating on an event-driven, serverless framework, this service supports numerous embedding models from BAAI, OpenAI, JinaAI, VoyageAI, etc. Enhanced with relay and cache mechanisms, it efficiently handles large volumes of data embedding requests within a minimal timeframe.
- RAG Service: This pivotal service with dynamic scaling feature facilitates the primary functionalities of RAG, including chat prompts, vector database searches, retrieval reranking, and essential features such as session management and configuration settings.
Middleware Layer
- Message Queue: Central to our scalable architecture, the message queue facilitates seamless data flow and task management across services.
- Cache: We leverage caching to share critical configurations between backend services, ensuring a fluid chat experience and efficient data streaming for multiple users.
- LLMs Integration: This component offers flexible configurations to integrate major Large Language Models like GPT, Claude, and Llama3 on the Epsilla Cloud, enabling users to harness these powerful models without any coding requirement.
Data Foundation Layer At the foundation of our architecture lies the Epsilla Vector Database, an AI-native vector search engine developed in C++ proven to be 10x faster and more accurate than alternatives (read more at https://blog.epsilla.com/benchmarking-epsilla-with-some-of-the-top-vector-databases-543e2b7708e5). With its serverless framework and separation of storage and compute layers, the database ensures exceptional throughput, reliability, and scalability for handling massive datasets.
Now let’s have a quick walkthrough how an end user experience looks like.
To create an ETL pipeline, users first select the source — from options like local files, AWS S3, SharePoint, Notion, or websites — and provide necessary credentials.
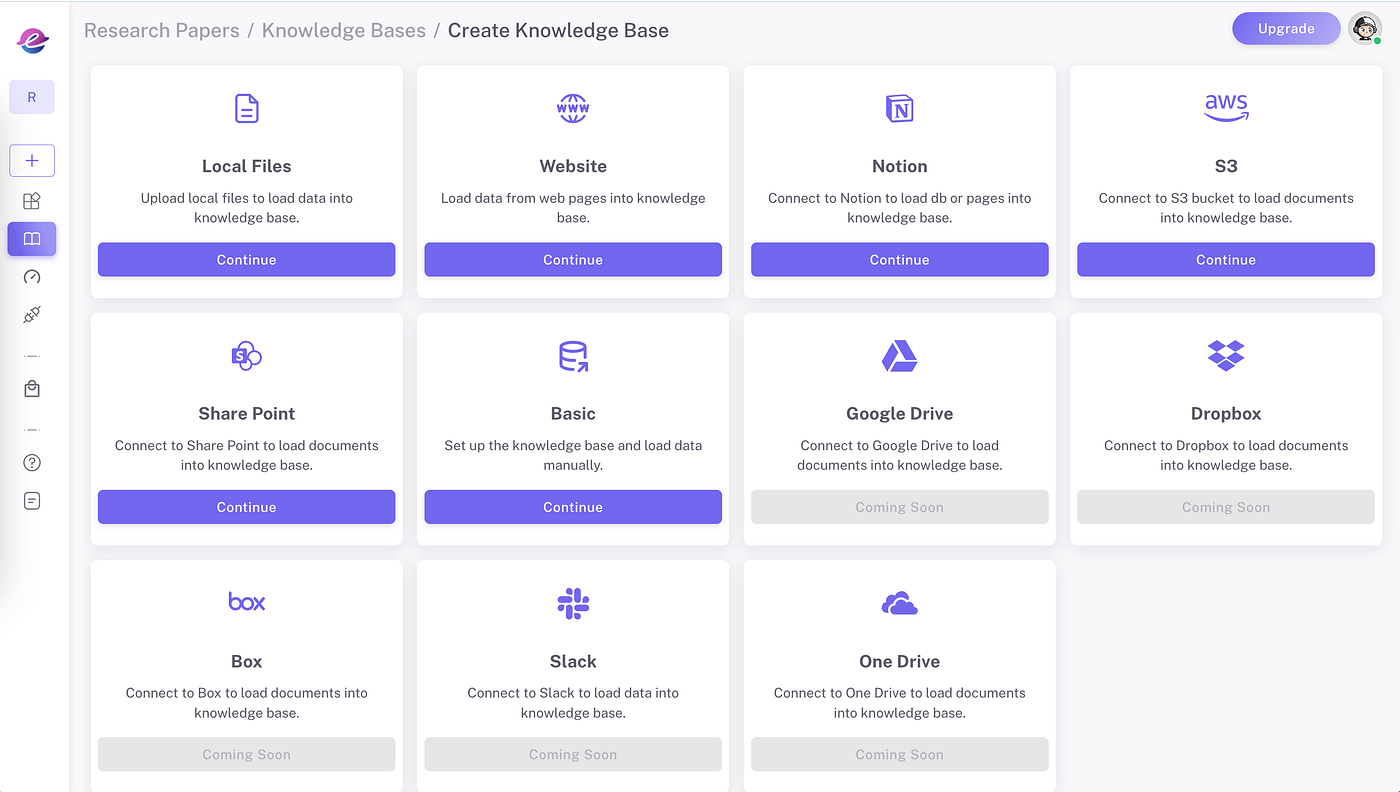
After selecting the source, click ‘Create’ to establish the pipeline with default settings. For sources like AWS S3 and SharePoint, the auto-sync feature can be enabled to periodically update the data. Here is how to load data from an AWS S3 bucket, as a practical example to get you started:
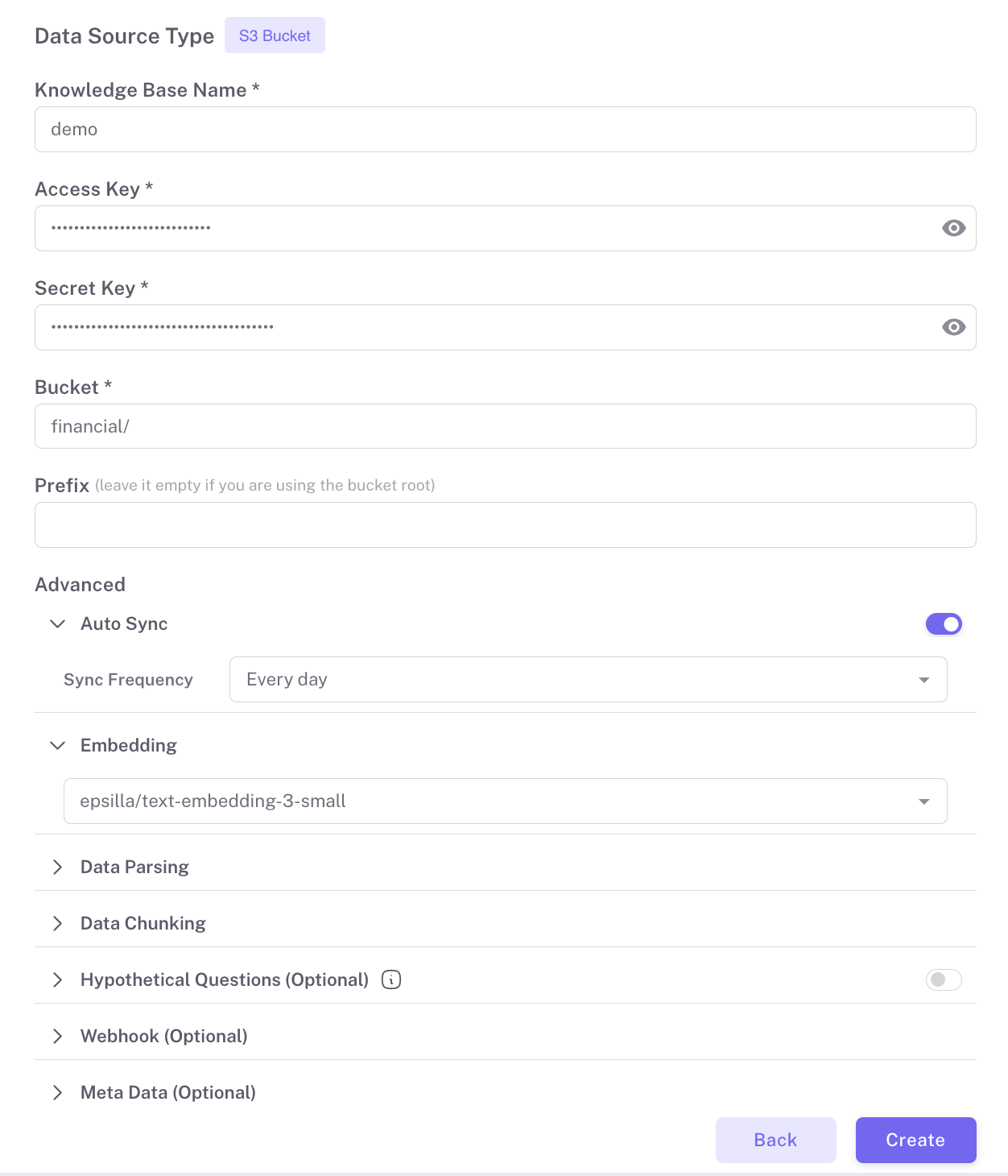
To tailor the ETL process to specific data handling needs, Epsilla offers customizable configurations. The default parsing method is set to ‘auto’, which automatically determines the most suitable parsing technique based on the data format. However, users have the flexibility to explicitly select relevant parsing options such as ‘PDF’, ‘CSV’, or ‘JSON’ depending on their specific data requirements. Additionally, Epsilla provides various chunking methods that can be switched based on the nature of your data, allowing for more efficient processing of large datasets or complex file types.
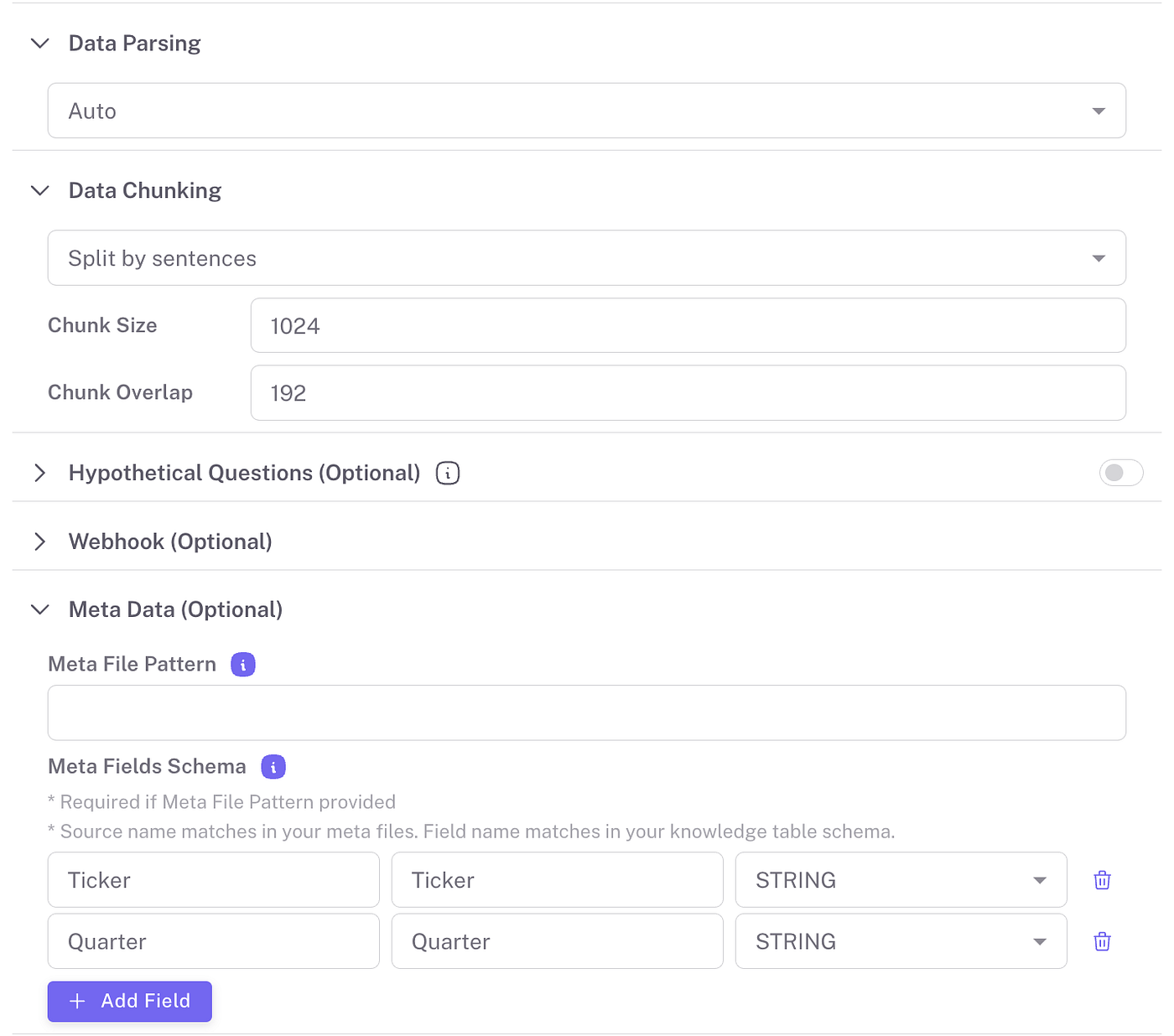
As the data loads into the system, users can monitor the progress of each file directly on UI. This real-time progress tracking ensures transparency and allows users to manage their data effectively, addressing any issues as they arise during the data loading process. This feature is particularly useful in large-scale data operations where the volume and variety of data can be overwhelming:

You can start creating RAG applications (including Chatbots or Smart Search) even before the data is fully processed. Learn more at how to build RAG chatbots and smart search apps using Epsilla:
Customer Stories
Epsilla’s large-scale Smart ETL for document loading and knowledge indexing architecture has empowered many customers to develop their RAG solutions, with the following examples representing just some of our success stories across various industries:
- Legal: A Legal-Tech company processed over 120,000 legal case files from court databases to create a junior legal assistant AI. This tool helps streamline the search and analysis of past cases, enhancing efficiency in new case processing.
- Construction: A Construction-Tech company managed the ingestion and analysis of tens of thousands of zoning law documents, some of which exceed 10,000 pages and several hundred MBs in size. They developed an AI assistant that leverages this data to aid in construction planning, ensuring compliance and strategic decision-making.
- Education: A Faith-Tech company used Epsilla to develop a AI-powered virtual study buddy providing a personalized and engaging conversational learning experience , incorporating thousands of books and annotations. This comprehensive tool aids faith-seekers, biblical students and scholars in their pursuit of knowledge on faith.
These case studies are just a sample of how Epsilla’s robust and scalable Smart ETL capabilities are transforming industries by enabling smarter, data-driven solutions. In addition to these sectors, our customers are also building their businesses in financial, healthcare, and many other industries.
Conclusion
In this blog, we’ve examined the challenges of implementing Large-Scale ETL for unstructured data in RAG systems. Epsilla’s RAG-as–a-Service platform addresses the critical hurdles in data management for AI-powered applications — ensuring efficient ingestion, processing, and synchronization. Our architecture enhances system performance and data accuracy, helping customers achieve measurable outcomes.
Looking to maximize the potential of your unstructured data with LLM? Sign up for FREE today at https://cloud.epsilla.com.
* This article is a joint effort with Eric Yang, Ricki Qin and Jay Yu.