

Today, we’re excited to announce our biggest update yet: Epsilla v0.1 — a scalable, fully distributed version of Epsilla.
Over the past several weeks, our team has been busy refactoring the Epsilla kernel and building a new distributed dispatching layer. This marks Epsilla’s first major release designed for production use, representing a big step forward for our platform.
What’s New in Epsilla v0.1
This latest version introduces powerful features enhancing both scalability and reliability.
- Firstly, we’ve integrated support for sharding vector data, enabling horizontal scaling to manage larger volumes of data efficiently.
- Alongside, we’ve supported configuring multiple replicas to support high availability (HA) and significantly boost throughput.
- Furthermore, we offer dynamic horizontal sharding expansion to accommodate data growth, along with automatic scaling of replicas in response to fluctuating traffic demands.
Despite these advanced enhancements, we’ve retained Epsilla’s user-friendly interface, ensuring that ease of use remains a cornerstone of our platform. Experience the new level of robustness and scalability with the simplicity you’ve always appreciated in Epsilla.
Architectural Shift
Prior to the release of v0.1, Epsilla was deployable solely as a single-node instance using the all-in-one Docker image. Data persistence was limited to local disk storage or mounted cloud storage solutions. Each database table operated as a single-shard instance, meaning the capacity for vector storage in each table was constrained by the memory and disk size of an individual machine.
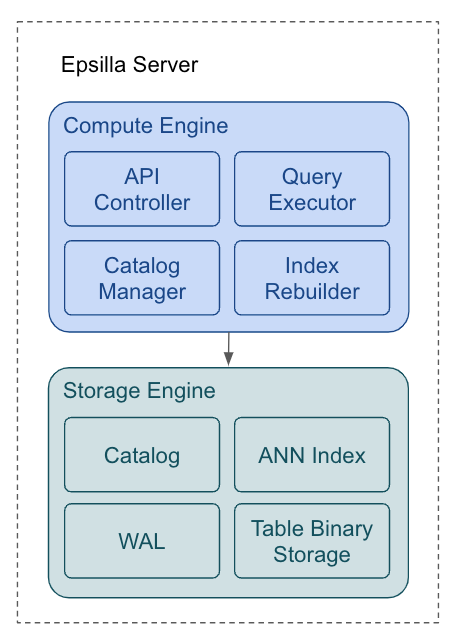
The single-node Epsilla server is divided into two primary components: the compute engine and the storage engine.
The compute engine is composed of four key elements:
- API Controller: This component is responsible for handling REST requests, including CRUD operations for data and catalog management.
- Catalog Manager: It manages the schemas for databases and tables, ensuring structured and organized data handling.
- Query Executor: This executor is dedicated to conducting high-performance Approximate Nearest Neighbor (ANN) searches and efficient data retrieval.
- Index Rebuilder: Operating periodically, this component rebuilds the ANN index to integrate data updates, maintaining the index’s effectiveness and accuracy.
The storage engine compartmentalizes data storage into four distinct sections:
- Catalog: This section holds the schemas for databases and tables.
- WAL (Write-Ahead Log): The WAL is crucial for ensuring data consistency and providing fault tolerance in the event of a database crash.
- ANN Index: This is where the graph indices reside, serving to accelerate ANN searches.
- Table Binary Storage: A specialized columnar format binary storage is used for storing the vector tables, optimizing both storage efficiency and access speed.
The architecture of Epsilla v0.1 is designed for distributed deployment, offering versatile setup options. It can be seamlessly deployed either as an on-premises Kubernetes (K8S) cluster or on managed cloud Kubernetes services such as Amazon EKS, Google GKE, Azure AKS, and others. When deployed in a cloud environment, Epsilla is engineered to integrate with block storage services like Amazon S3, Google Cloud Storage (GCS), and Azure Blob Storage (ABS), leveraging these platforms for robust and scalable data storage solutions.
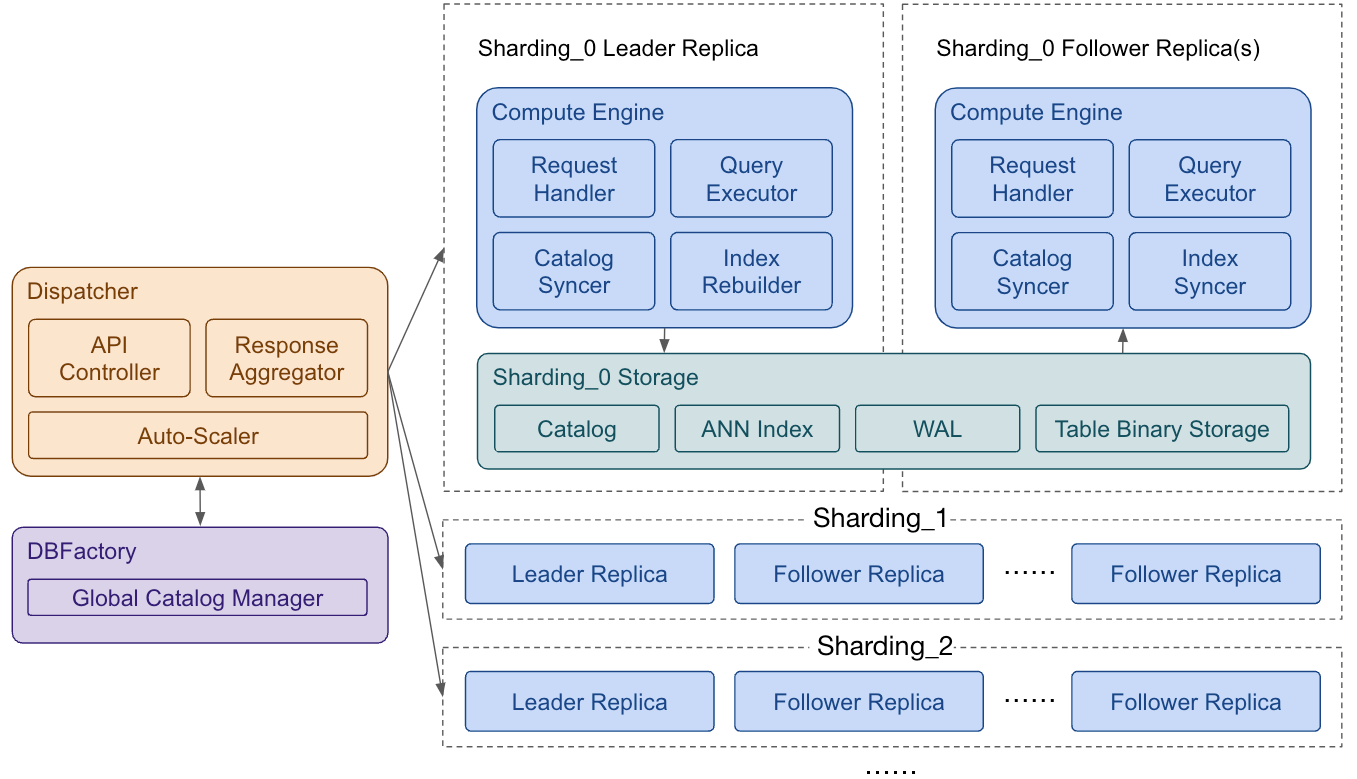
At the heart of the Epsilla system lies the dispatcher, which orchestrates the entire operation.
- DBFactory manages a multi-tenant catalog, ensuring efficient handling of all database instances.
- Response Aggregator plays a crucial role in compiling partial responses from various shardings and seamlessly merging them to produce the final outcome.
- Auto-Scaler adeptly increases the number of shardings in response to data growth. It also dynamically adjusts the number of replicas for each sharding. This adjustment is based on the traffic elasticity, adhering to the configured minimum and maximum replica limits.
In this architecture, each sharding’s replica is encapsulated within a Kubernetes pod. We’ve architecturally separated compute and storage functions, while ensuring that all replicas of a sharding access a shared storage copy.
- The leader replica bears the responsibility of rebuilding the ANN (Approximate Nearest Neighbor) index and synchronizing data back to the storage system.
- Concurrently, follower replicas are engaged in passive synchronization of the graph index, thereby enhancing the efficiency and speed of ANN searches.
Deploying and Using Epsilla in Distributed Mode
The distributed mode deployment of Epsilla will be accessible in the upcoming GA release of Epsilla Cloud. It is currently available through the Epsilla Enterprise package.
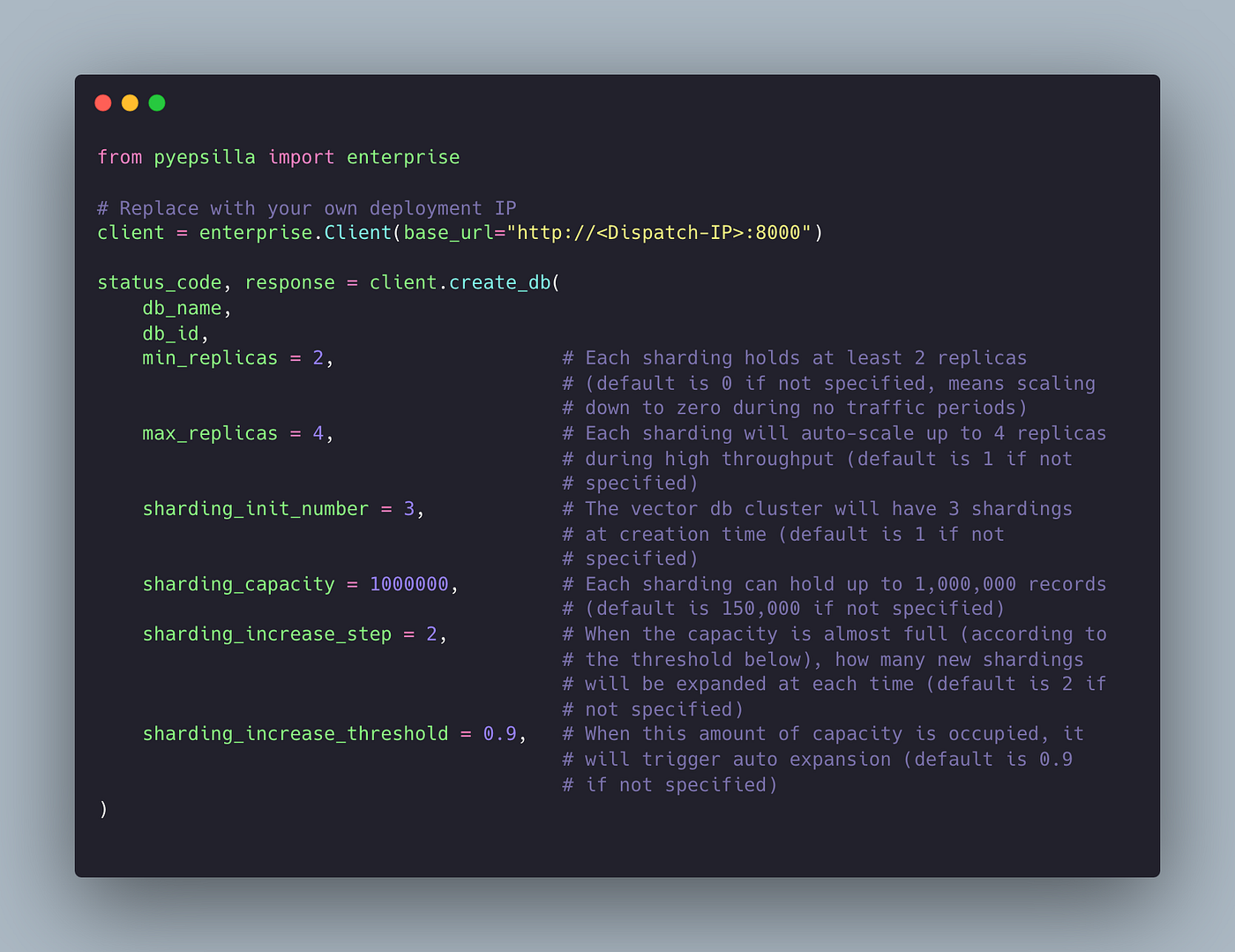
Talk to us or join our Discord community and ask for the Epsilla Enterprise package. This package is equipped with detailed deployment guidance and sample code to assist you. Here is a Python code snippet to demonstrate how to provision a distributed Epsilla cluster with advanced sharding and replica configuration options:
Contributing
We deeply appreciate the community’s involvement and contributions. With the release of our most significant update to date, it’s the perfect opportunity to start contributing to Epsilla. Explore our projects on GitHub, and connect with us and fellow enthusiasts on Discord. Your insights and participation are what drive Epsilla forward!