

Demystifying RAG-Empowered Chat Agents: Aligning Questions and Documents with HyDE
Unleashing the Power of AI Chat Agents for Your Business
In today’s digital world, AI chat agents are more than helpful tools — they’re now essential for businesses aiming to provide fast, responsive customer support and connect with users. But how do these chat agents seem to understand questions so accurately? The answer lies in how they interpret your queries and connect them with the information they hold.
This article unpacks Hypothetical Document Embeddings (HyDE) — an advanced Retrieval-Augmented Generation (RAG) optimization that reshapes chat agent’s performance. Let’s explore how HyDE allows chat agents to align your questions with their knowledge base, transforming the way they communicate with users.
The Challenge of Misalignment in AI Chat Agents
A big challenge in traditional embedding-based search systems is something called misalignment — basically, a mismatch between how user questions and documents are represented in the embedding space. Ideally, an embedding model should “get” the main patterns in both questions and documents, putting them into a shared space so that it can easily match questions with the closest relevant documents.
But in reality, it’s not so straightforward. Documents are often written in a descriptive, storytelling style, while questions tend to be direct and follow an interrogative sentence structure. This difference in style can throw the model off, especially if it’s not perfectly trained to handle both. Instead of creating a nice overlap between question and document embeddings, they might end up a bit “off” from each other. This means that when you ask a question, the model might pull up documents that aren’t quite what you were looking for, because the question and document embeddings are just a little too far apart in the embedding space.
Imagine it like recognizing faces in a crowd. If you’re not familiar with everyone, all the faces might start to look the same from a distance. But if you know them well, each face has unique features. In embedding spaces, this “distance” can lead the model to miss some of the subtle connections between certain questions and the most relevant documents. This is exactly the gap that HyDE bridges by generating hypothetical documents. With these hypothetical documents, it helps align the question and document spaces, making sure the system can find exactly what you’re looking for.

For more information about embedding, please read: [How Do AI Agents Actually “Understand”? Discover Embeddings and Vector Search](https://epsilla.com/blogs/how-do-ai-agents-actually-understand-discover-embeddings-and-vector-search)
HyDE: A Solution to the Misalignment Problem
Hypothetical Document Embeddings (HyDE) are a breakthrough in tackling this misalignment.
Well, there are two main ways to tackle misalignment: either bring the question closer to the document space or pull the documents closer to the question space. HyDE takes the first approach — bringing the question into the document space — and does this with a clever trick called hypothetical embeddings.
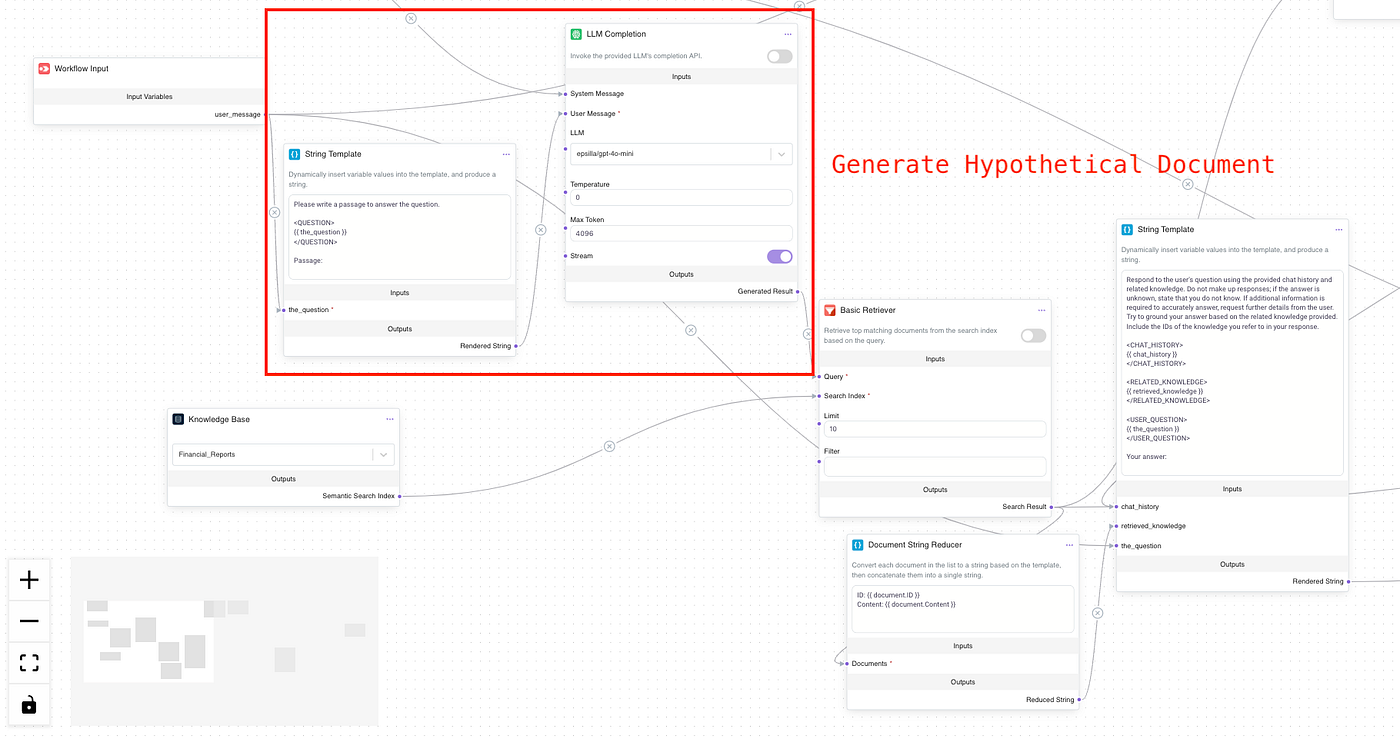
Here’s how it works: when a question comes in, HyDE generates a “hypothetical document” as a sort of placeholder. Imagine we just let the model produce a document based on the question without trying to search for anything just yet. The large language model (LLM), trained on tons of Q&A data, gives a “hallucinated” document in a descriptive, narrative format. This document isn’t meant to be the final response but acts as a bridge. Because it’s similar in style to the actual documents, this hypothetical document can more easily “match” the patterns in the document space.
By creating this hypothetical document, we essentially “pull” the question closer to where the actual documents are. Then, when we perform the search, there’s a much better chance of finding documents that match this hypothetical document closely, leading to a more relevant response. This is HyDE’s strategy for tackling misalignment: using the LLM to generate a document that “speaks the language” of the knowledge base, ensuring the system can find the right information more effectively.
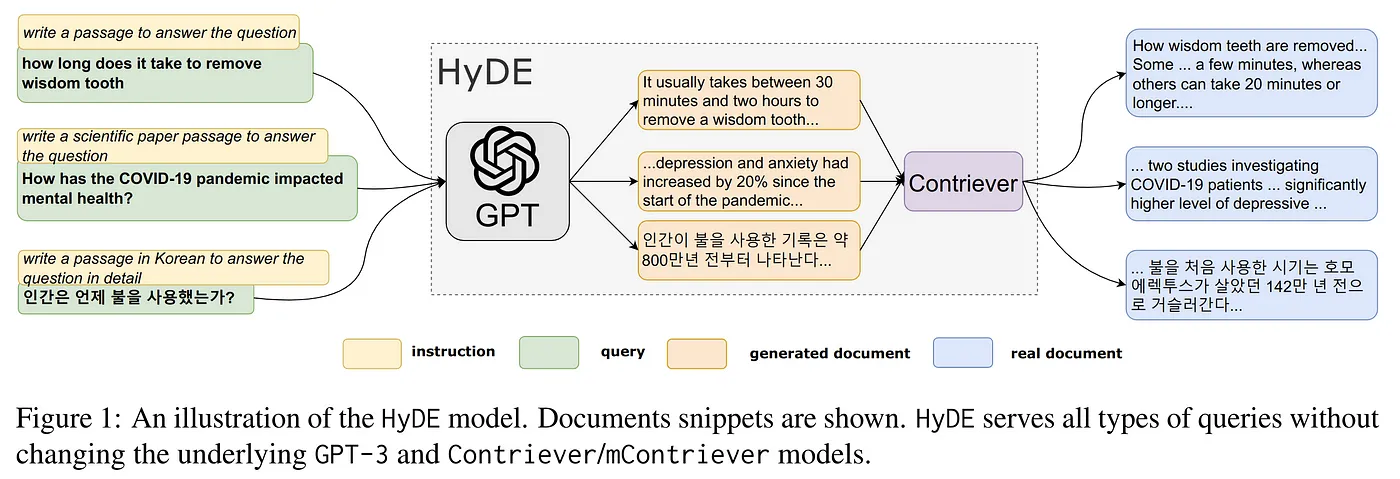
Here’s a step-by-step rundown:
You Ask a Question: Let’s say you wonder, “How can I improve my credit score?”
Generating a Hypothetical Document: Instead of immediately searching for an answer, the chatbot first generates a detailed hypothetical document. Something like, “You can boost your credit score by paying your bills on time, reducing your debt, and avoiding new credit inquiries.”
Turning That Document into an Embedding: This hypothetical document is then converted into a special code, or embedding, that captures its core meaning.
Searching for Similar Content: Using this embedding, the system searches through a database to find real documents that are similar to the hypothetical one.
Crafting the Final Response: Finally, the chat agent uses these relevant documents to give you an accurate and helpful answer via RAG.
By focusing on (hypothetical)document-to-(actual)document similarities, HyDE bridges the gap between what you ask and the information available, making the whole interaction smoother and more effective.
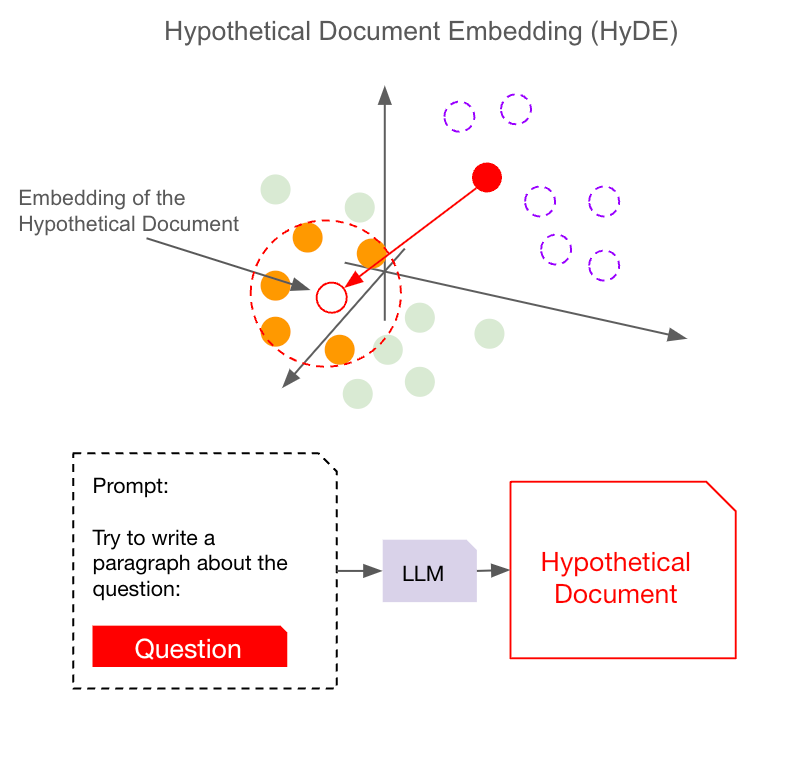
How Basic HyDE Elevates Chat Agent Interactions
Why Is HyDE So Effective?
The genius of HyDE lies in its ability to operate without extensive training data. Traditional systems need tons of labeled examples to understand different ways a question can be asked. HyDE, on the other hand, uses powerful language models to generate hypothetical documents on the fly, which then guides the search for real information. This makes it adaptable, flexible, and effective across various topics and even different languages.
Example:
- Question: “What are the health benefits of green tea?”
- Hypothetical Document Generation: “Green tea is rich in antioxidants, improves brain function, aids in fat loss, and may lower the risk of certain cancers.”
- Embedding and Retrieval: The chat agent searches for documents related to these benefits.
- Response: You receive a clear, informative answer on green tea’s health advantages.
This approach ensures that the chatbot not only understands the question but also responds with information that feels relevant and valuable.
Comparative Analysis of Workflow: With and Without HyDE
You can easily enable or disable HyDE in Epsilla’s knowledge retriever configuration settings.
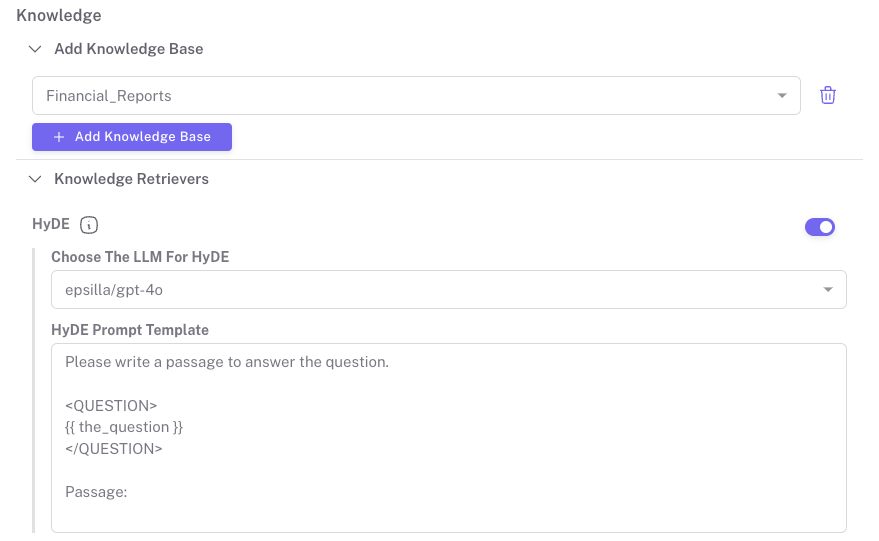
You can also toggle the Edit Workflow to reveal what’s happening behind the scenes.

In the workflow without HyDE, the user’s question is directly sent to the basic retriever. This process is straightforward, with the retriever extracting relevant information from the knowledge base without any preprocessing or context generation. The retrieved data is then directly inserted into the prompt for response generation. However, this method has limitations, as the system relies solely on matching the question with existing documents, which may result in responses that lack relevance and fail to capture the user’s true intent due to misalignment between the user question and documents in the knowledge base.
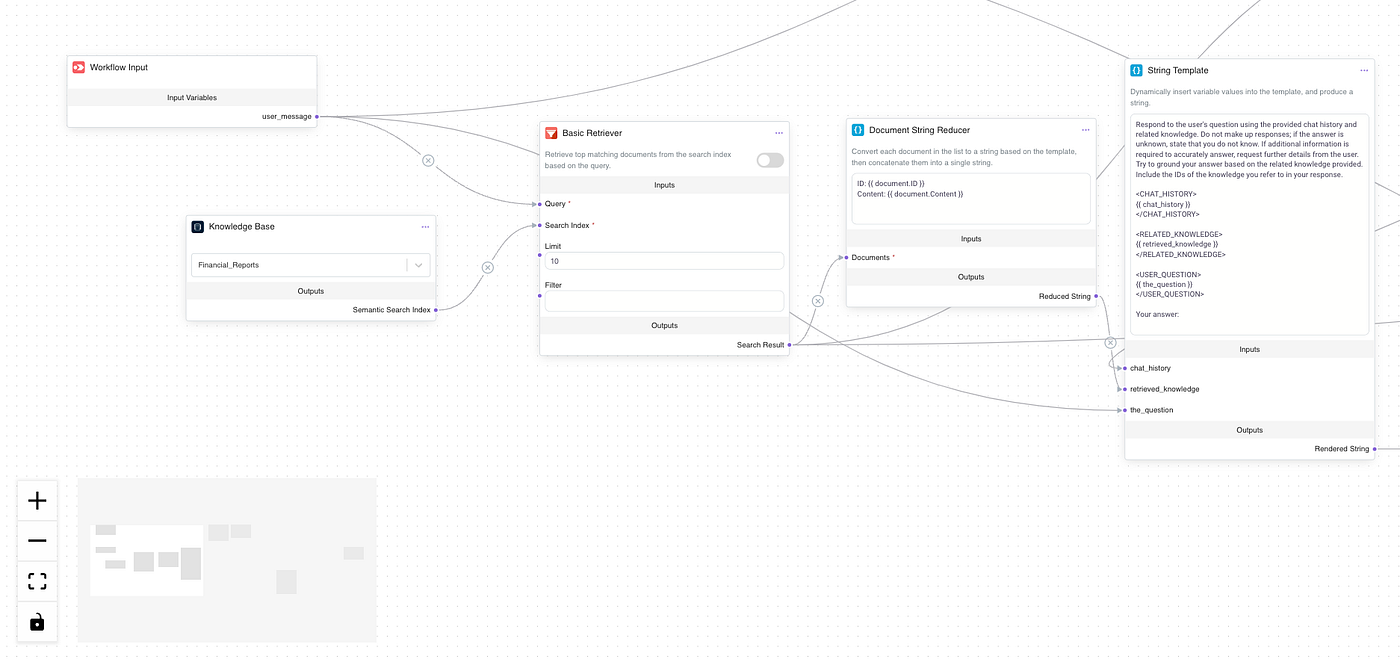
In contrast, enabling HyDE adds an extra step to the workflow, significantly enhancing the quality of information retrieval. In this case, the user’s question first undergoes a generation process where the model creates a hypothetical document based on the original question. The key here is that the generated document is more descriptive, providing rich context for the subsequent retrieval step. After this processing, the generated document is used to guide the retrieval, allowing the system to find documents that better align with the user’s intent. Therefore, this enhanced workflow not only improves the alignment of retrieved information with user needs but also leads to more accurate and satisfying responses.
Tackling the “Hallucination” Problem
Now, HyDE isn’t without its challenges. One issue is the so-called “hallucination” problem.
In the context of language models, hallucination happens when the AI generates information that’s off-base or incorrect because it lacks specific domain knowledge. If the LLM starts hallucinating, it might give you a hypothetical document that is irrelevant or entirely inaccurate, which can be misleading and harm the final RAG performance.
Iterative HyDE: Taking Accuracy to the Next Level
To minimize these limitations, we introduce the Iterative HyDE approach, which refines chat agent accuracy, especially for technical or domain-specific queries.

How Iterative HyDE Works:
While basic HyDE works well for general questions, it can struggle with domain-specific queries, like finance or healthcare, because it generates hypothetical answers based on public training data. This sometimes leads to answers that don’t fully capture the specialized patterns in these fields.
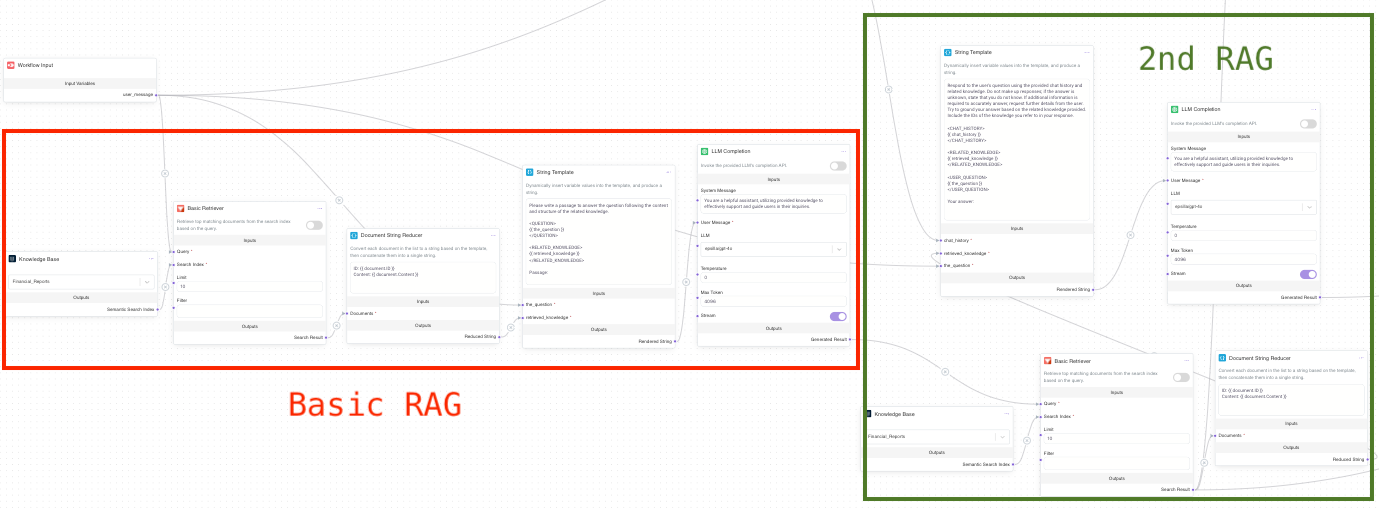
To address this, Iterative HyDE adds an extra step. First, it performs a basic RAG (Retrieval-Augmented Generation), pulling up some initial documents from the knowledge base — even if they aren’t perfectly accurate, they still contain relevant domain knowledge. This grounding helps the model generate a more aligned hypothetical document. Then, this hypothetical document goes through a second embedding and retrieval step, allowing for a more precise, field-specific search.
In short, iterative HyDE RAG twice: the first round establishes a general understanding of the domain, and the second round sharpens the answer for accuracy. This improved method makes HyDE more effective at tackling complex, specialized questions.
While the basic agent setting in Epsilla doesn’t support iterative HyDE out of the box, you can easily implement it using Workflow Customization by dragging and dropping the necessary components:
Wrapping Up and Looking Ahead
HyDE is revolutionizing the way chat agents and search engines understand and respond to user’s questions. By generating hypothetical documents and using them to find the most relevant information, it creates a more accurate and better quality RAG experience. So the next time you get a spot-on answer from a chat agent, there’s a good chance HyDE is working behind the scenes!
What’s Next?
In our next article, we’ll look at aligning question and document embeddings with hypothetical questions. This approach takes the flip side of the same coin — generating potential questions that could be asked from each chunk of your documents to better align with actual user questions. Stay tuned to see how this method can further enhance chat agent functionality.