
Advanced RAG Optimization: Aligning Question and Document Embedding Spaces with Hypothetical Questions

Welcome back to our series on demystifying RAG (Retrieval-Augmented Generation) chat agents. In [our previous article](https://epsilla.com/blogs/demystifying-rag-empowered-chat-agents-aligning-question-and-document-embedding-spaces-with-hyde), we discussed how aligning questions and the HyDE (Hypothetical Document Embeddings) strategy can improve the performance of chat agents by bridging the semantic gap between user queries and document content.
Today, we’re shifting gears to explore another innovative approach: Hypothetical Questions. This method flips the traditional process by generating potential questions from document chunks themselves. We’ll discover how this strategy tackles specific challenges, especially the misalignment between user questions and document embeddings, and how Epsilla leverages this technique to boost accuracy and user satisfaction.
Understanding Hypothetical Questions
What Are Hypothetical Questions?
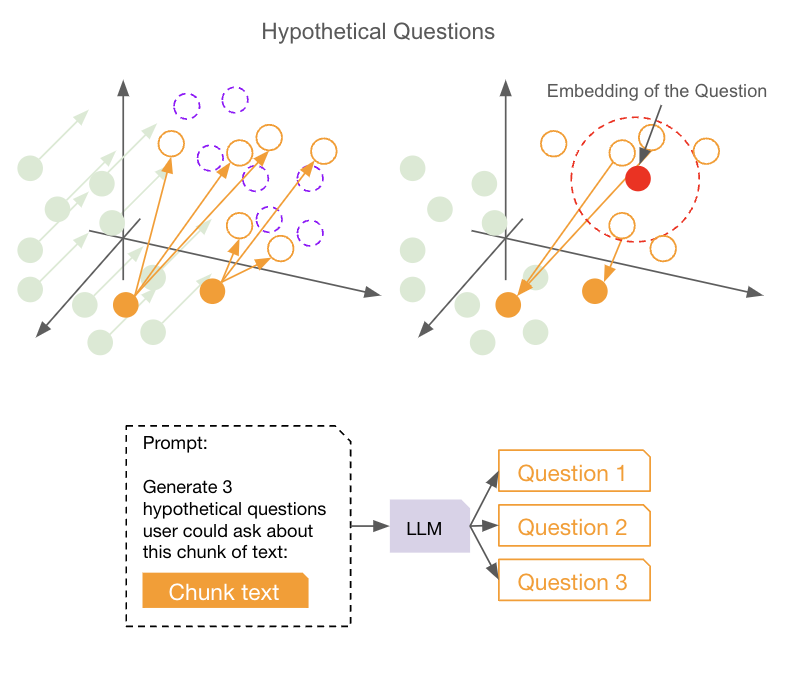
Hypothetical Questions involve using a large language model (LLM) to generate possible questions that could be asked for each chunk of a document. Instead of embedding the document chunks directly, we embed these generated questions into vector embeddings. When a user asks a question, we compare their query to these hypothetical question embeddings to find the most relevant questions, then follow the back link to retrieve the original document chunks associated with these questions.
This approach addresses a key issue: the misalignment between the embeddings of user questions and document chunks. Since the embeddings of questions and answers can exist in different vector spaces (read more about the misalignment problem between questions and documents in [our previous article](https://epsilla.com/blogs/demystifying-rag-empowered-chat-agents-aligning-question-and-document-embedding-spaces-with-hyde)), directly comparing them may not yield the most accurate results. By transforming document chunks into questions, we ensure that we’re comparing “apples to apples,” leading to better alignment and more precise retrieval.
Problems Addressed by Hypothetical Questions
✨Solving Misalignment in Embeddings
One of the biggest challenges in RAG systems is the misalignment between the embeddings of user queries and the embeddings of document chunks. User questions and document content often reside in different parts of the semantic space, making it hard for the system to accurately match them.
Hypothetical Questions tackle this problem head-on. By generating questions from each document chunk, we create embeddings that are in the same semantic space as the user’s question. This means when we perform a similarity search, we’re comparing the user’s question to other questions, not to answers or statements. This alignment significantly improves the accuracy of our retrieval process.
🪐Making Retrieval More Accurate
Imagine you’re trying to find detailed information on health insurance coverage for specific medical procedures. If the system only uses embeddings from a large policy document, your query, “Does my insurance cover knee surgery and associated physical therapy?” might not precisely match the embedded content due to varying semantics and phrasing in the document. However, if the system has generated hypothetical questions such as “Is knee surgery covered under this policy?” or “Does the insurance include physical therapy for post-surgical recovery?”, your query will more closely align with these hypothetical embeddings, improving retrieval accuracy and ensuring you quickly find the information you need.
How Does This Work Behind the Scenes?
Step-by-Step Process
Document Chunking: We split the original document into manageable chunks.
Generating Hypothetical Questions: For each chunk, we use the LLM to generate several potential user questions.
Embedding Questions: We convert these hypothetical questions into vector embeddings.
Storing Embeddings with Metadata: We store the embeddings in a vector database and include metadata that links back to the original document chunks.
User Query Processing: When a user asks a question, we embed their query.
Similarity Search: We compare the user’s query embedding with the hypothetical question embeddings to find the closest matches.
Retrieving Relevant Chunks: Following the metadata of chunk links, we trace back the corresponding original document chunks.
Generating the Response: We use these chunks as context to generate a precise and relevant answer.
Epsilla’s Approach to Hypothetical Questions
Step 1. Enable Hypothetical Questions in DATA SOURCES
In Epsilla, you can enable Hypothetical Questions in your Data Source settings. This tells the system to generate hypothetical questions during data loading. Our default LLM and prompt are good enough for generic use cases, but feel free to customize them to fit your domain-specific needs.

Step 2. Question Generation in DATA STORAGE
During data loading, for each chunk of your document, Epsilla uses the language model to generate several hypothetical questions.
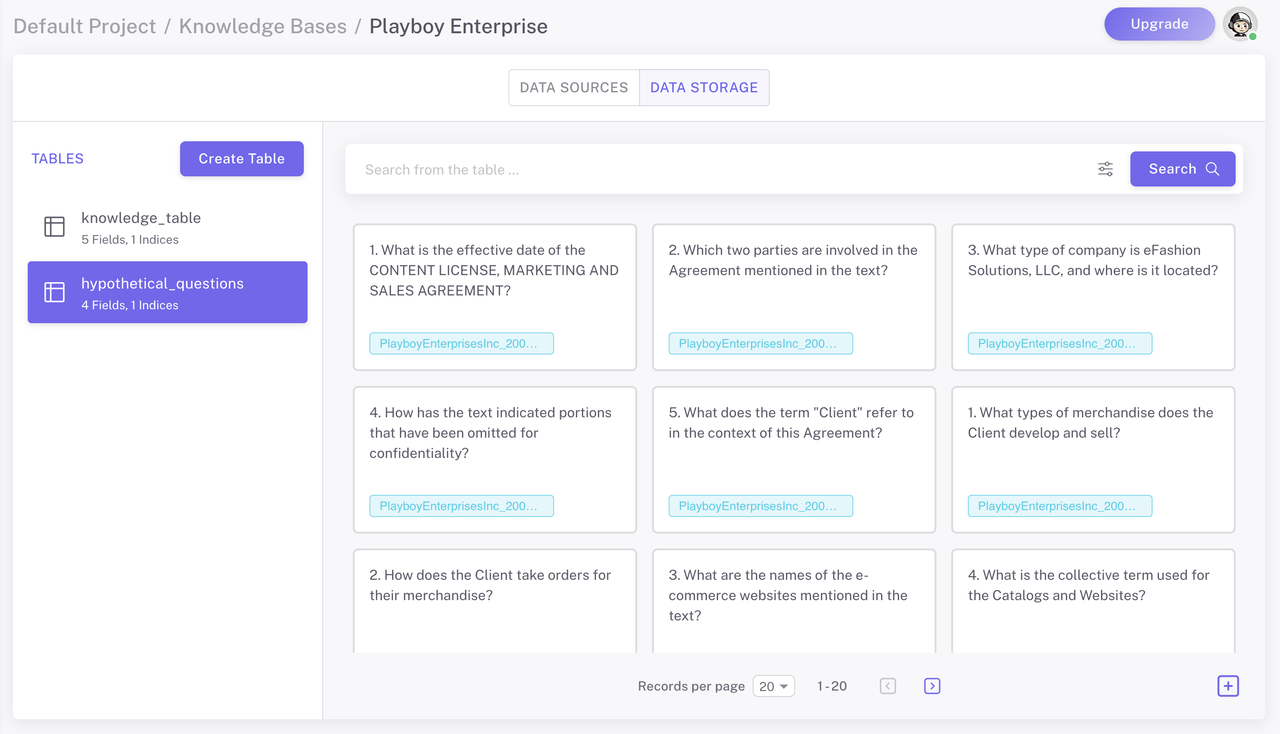
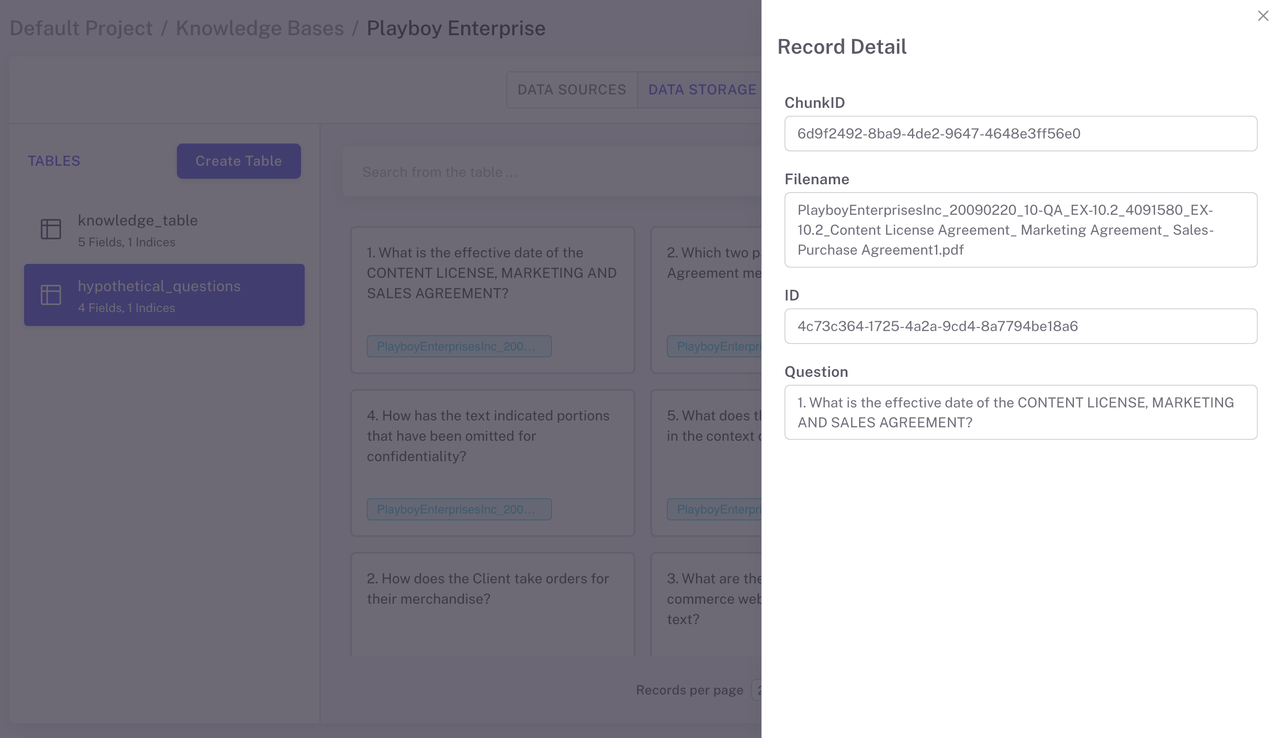
These questions are stored in a separate table, each linked back to the corresponding chunk (ChunkID).
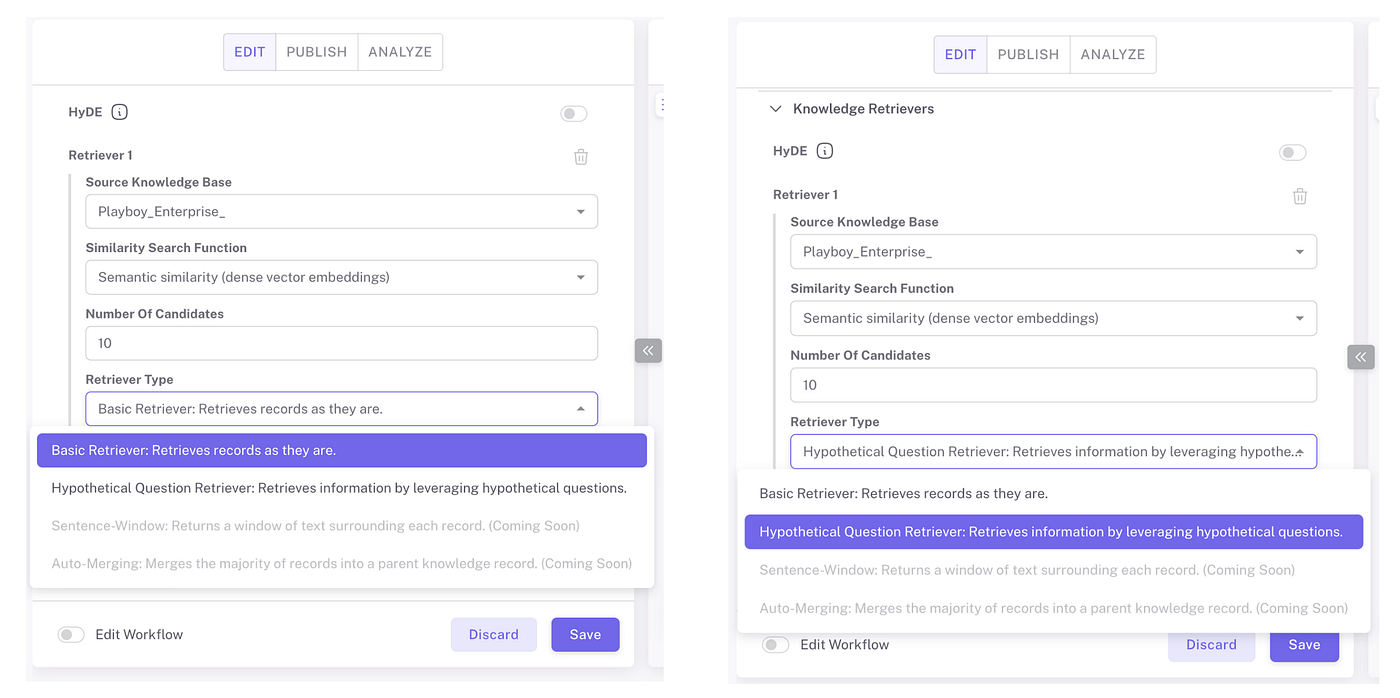
Step 3. Adjusting the Retriever
After enabling Hypothetical Question in your DATA SOURCE, the next step is to adjust the retiever in your agent settings to apply this new strategy.
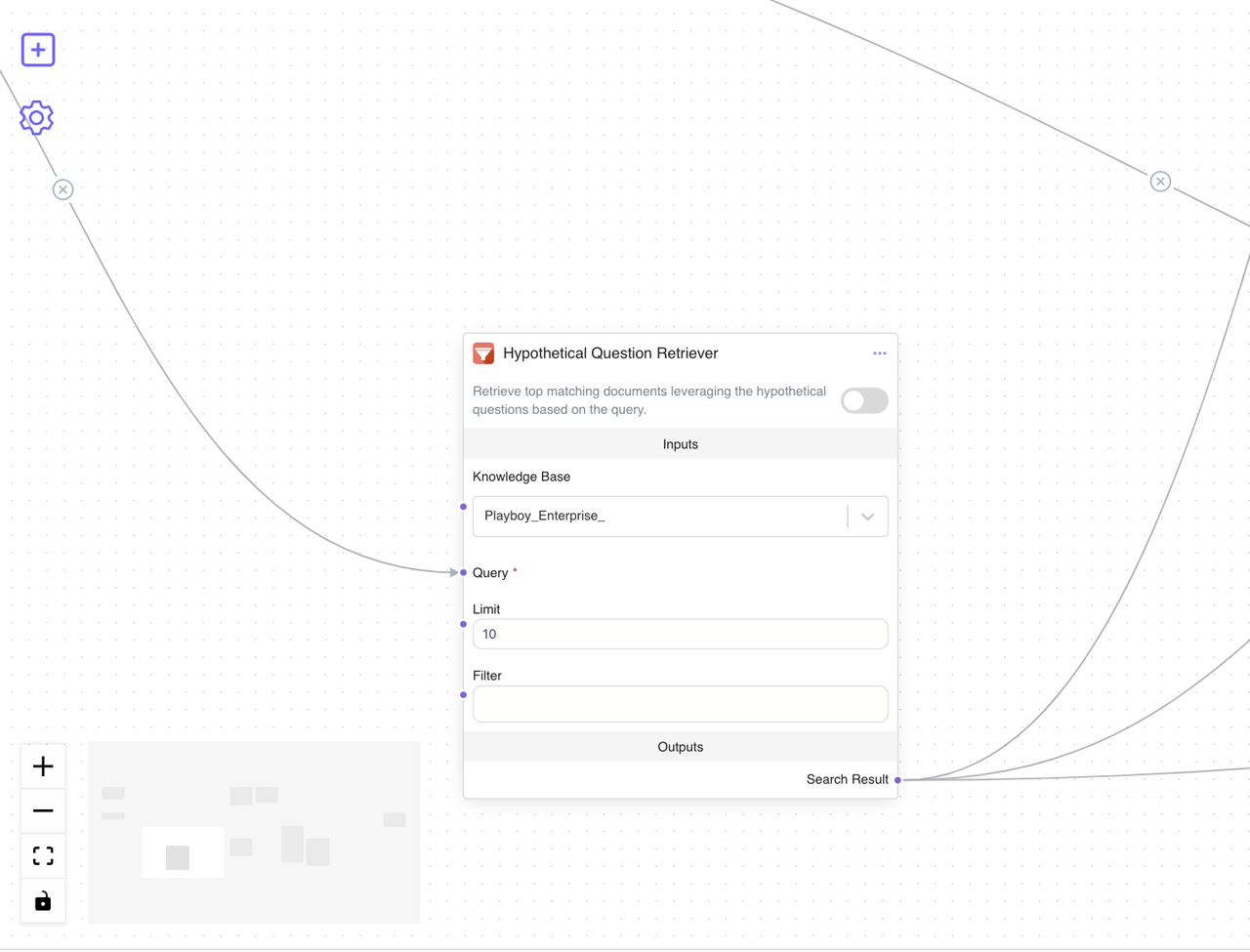
1️⃣Set the Retriever Type: In the agent configurations, specify the retriever type to use the Hypothetical Question Retriever (the image on the left)
2️⃣Comparing with the Basic Retriever: To understand the effectiveness of the Hypothetical Question Retriever, we’ve also built a comparison of it (the image on the right) with the basic retriever (the image on the left). This allows us to test and observe the differences in performance between the two methods.
Step 4. Visualizing the Workflow
You can toggle on Edit Workflow to see what’s happening behind the scenes. When you use the Hypothetical Question Retriever in your agent, the workflow will display a Hypothetical Question Retriever node for this step. This block in the workflow helps you understand and trace the retrieval process.
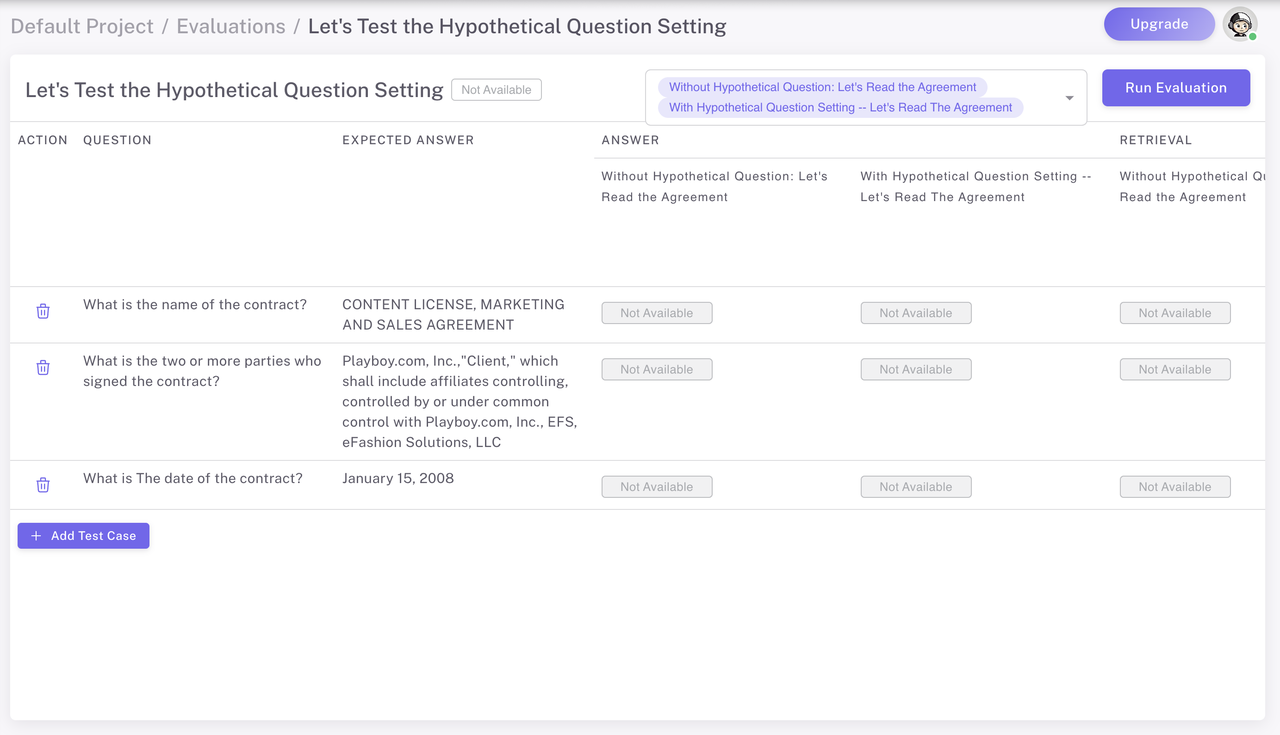
Step 5. Evaluating the Results — Case Study: Testing with Playboy Enterprise, Inc. Content License Agreement
To evaluate the effectiveness of the Hypothetical Question Retriever compared to the Basic Retriever, we conducted a case study using a real-world document: the Content License Agreement from Playboy Enterprises, Inc.
The Scenario
We wanted to see how well our agents could extract specific information from a legal contract. We asked both agents the following three questions and provided the expected answers to assess their performance:
1. What is the name of the contract?
Expected Answer: CONTENT LICENSE, MARKETING AND SALES AGREEMENT
2. Who are the two or more parties who signed the contract?
Expected Answer: [http://playboy.com/](http://playboy.com/), Inc.,”Client,” which shall include affiliates controlling, controlled by or under common control with [http://playboy.com/](http://playboy.com/), Inc., EFS, eFashion Solutions, LLC
3. What is the date of the contract?
Expected Answer: January 15, 2008
To see how effective the Hypothetical Question Retriever is compared to the Basic Retriever, we set up an evaluation in Epsilla. We created two agents:
Agent A: Without Hypothetical Question Retriever — Basic Retriever
Agent B: With Hypothetical Question Retriever
We then ran a series of tests to compare how each agent retrieves content and the accuracy of their responses.
Using Epsilla’s evaluation feature, we measured several key metrics: Answer Correctness, Answer Relevance, Answer Faithfulness, Context Precision, Context Coverage

From the bar chart, you can see that the yellow bars (Agent A with Hypothetical Questions) are noticeably higher than the red bars (Agent B without Hypothetical Questions) in all categories. The evaluation clearly shows that using the Hypothetical Question Retriever enhances the performance of our chat agents. By aligning the embeddings and effectively addressing the misalignment problem, we achieve better accuracy and user satisfaction.

Conclusion
Hypothetical Questions offer a practical solution to the problem of embedding misalignment in RAG systems. By generating and embedding questions from document chunks, we ensure that user queries are compared within the same semantic space, leading to more accurate and relevant responses.
At Epsilla, we’ve successfully implemented this strategy, resulting in improved accuracy, better user satisfaction, and enhanced system performance. This approach complements the techniques we discussed in our previous article and represents a significant step forward in the development of intelligent chat agents.
What’s Next?
We’re continually exploring new methods to enhance the capabilities of our chat agents. Stay tuned for our next article, where we’ll discover multiple strategies for even better results.