
Benchmarking Epsilla Against Top Vector Databases
Epsilla (https://www.epsilla.com/) is a high-performance open-source vector database. Instead of building on top of the HNSW index, like most other vector database vendors, we’ve implemented a new approach that leverages parallel graph traversal technology to provide lower query latency.
Motivation
We respect the significant efforts that top vector database vendors have put into their products. They likely have added many optimizations to their own HNSW implementations. Thus, we want to conduct an end-to-end benchmark on query latency and throughput to observe Epsilla’s performance in real traffic.
Experiment Setup
In this benchmark, we used the gist-960-euclidean dataset, which consists of 1 million vectors. We tested with top 10 and top 100 nearest neighbor searches, using 1, 2, 4, and 8 concurrent search threads.
We set up two EC2 instances: one 4C8G machine served as the testing client to run the benchmark framework (our framework is derived from MyScale’s work), and another 16C32G machine ran the vector DB engines. The two machines were connected via a local network to minimize network latency during the benchmark.
We compared Epsilla with some of the top open-source vector databases (Qdrant, Weaviate, Milvus). All vector engines ran in Docker.
Query Latency
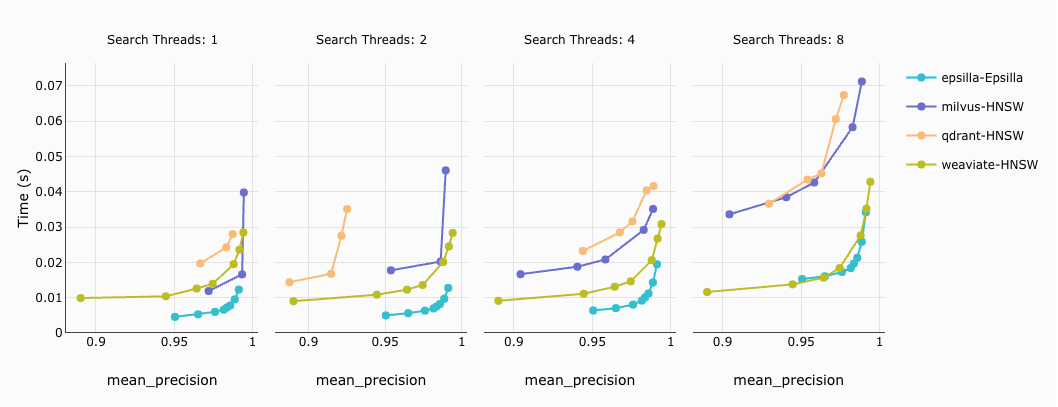
Top K = 10 query latency against different precision targets:
2. Top K = 100 query latency against different precision targets:
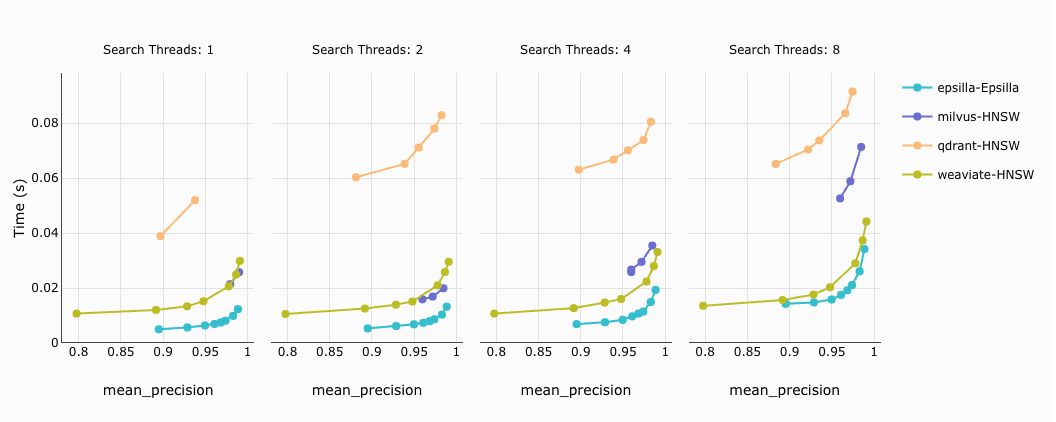
How to read the diagram: For the same target precision (same X-axis value), the lower the latency (the lower the Y-axis value), the better the performance of the vector database engine.
Conclusion: Within a 95% — 99% precision target, Epsilla outperforms all other vector database vendors by up to 10x.
Query Throughput
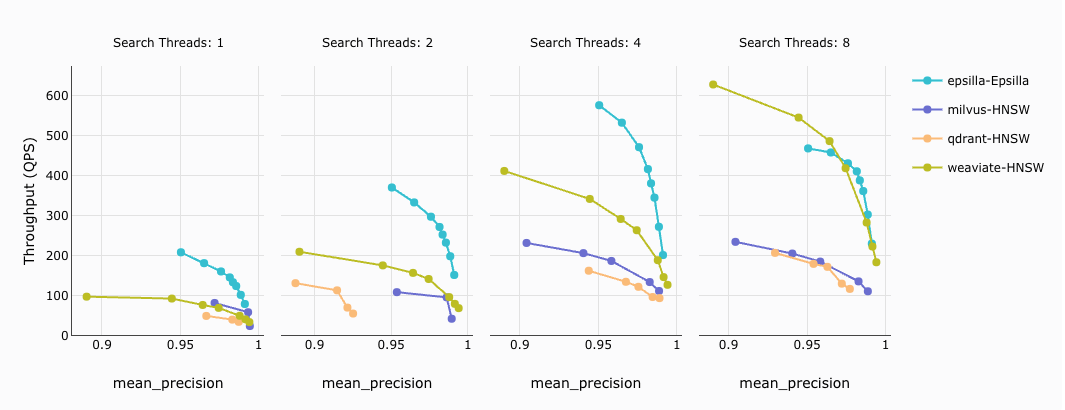
Top K = 10 query throughput against different precision targets:
2. Top K = 100 query throughput against different precision targets:

How to read the diagram: For the same target precision (same X-axis value), the higher the throughput (the higher the Y-axis value), the better the performance of the vector database engine.
Conclusion: Within a 95% — 99% precision target, Epsilla outperforms all other vector database vendors by up to 5x.
Are we biased?
We strive to be as objective as possible and have continually adjusted the parameters of various vector database vendors to optimize their performance. Although they all use the HNSW index, identical parameter values don’t yield the same precision. However, we are not experts in every vector database, so we might have overlooked important tweaks specific to certain vendors.
To ensure an apples-to-apples comparison, we excluded Pinecone since they only provide a SaaS offering. Firstly, we can’t control the machine size to exactly match our environment. Secondly, the network latency differs, making the comparison potentially unfair.
We also didn’t include non-native vector databases (such as pgvector, Elastic, etc.) in the comparison, as there are existing benchmarks (like https://qdrant.tech/benchmarks/) that show native vector databases outperform non-native ones by at least an order of magnitude.
Future work
We started just one month ago and it’s still pretty early; we haven’t leveraged all the possible optimizations yet. Moreover, we’ve focused on benchmarking one dataset (gist-960-euclidean). We will gradually add more datasets and support additional features.
We will also open-source our benchmark code soon, so everyone can try it out and help us identify our blind spots.
Please follow us at https://github.com/epsilla-cloud/vectordb and stay tuned!
Want to learn more? Join our Discord community: https://discord.gg/cDaY2CxZc5
Acknowledgements
- MyScale benchmark framework: https://github.com/myscale/vector-db-benchmark
- Qdrant benchmark framework: https://github.com/qdrant/vector-db-benchmark
- ANN benchmark: https://github.com/erikbern/ann-benchmarks