
Ever wondered how to make AI agents smarter and more efficient? The key lies in delivering knowledge with precision. When an AI agent fetches information, ensuring that the most relevant knowledge chunks appear at the top is critical for accuracy and performance. That’s where Epsilla’s reranking methods shine — prioritizing relevant insights so your agents can provide better responses, faster. Let’s dive into how Epsilla’s advanced reranking capabilities optimize knowledge retrieval and enhance agent outcomes!
1. What is Reranking, and Why Should You Care?
Reranking is the secret sauce for prioritizing the best knowledge chunks. In Retrieval-Augmented Generation (RAG), a search retrieves multiple results, but not all of them are equally relevant. Reranking reorganizes these results, ensuring the top slots are filled with the most accurate and contextually useful information. This process is vital for AI agents that rely on precise data to generate their answers, minimizing irrelevant noise and maximizing efficiency. With Epsilla’s reranking methods, your AI agent becomes a sharper, faster tool for uncovering the insights you need.
2. The Power of Hybrid Search and How Reranking Enhances It
Hybrid Search: The Best of Both Worlds
Hybrid search is like a powerful combo of different search methods. It combines traditional keyword matching (which works by finding exact words) with semantic search, which understands the context and meaning behind your query. Think of it as having the best of both worlds: precision from keywords and deep understanding from semantics.
In a hybrid search system, different retrievers go out and gather documents from various sources. Some of them rely on keywords, while others understand the deeper meaning behind your query using vector embeddings. Once these retrievers bring back their results, reranking comes in to sort everything out. The reranker looks at both your query and the content of the documents to decide which ones are the most relevant and should appear at the top.
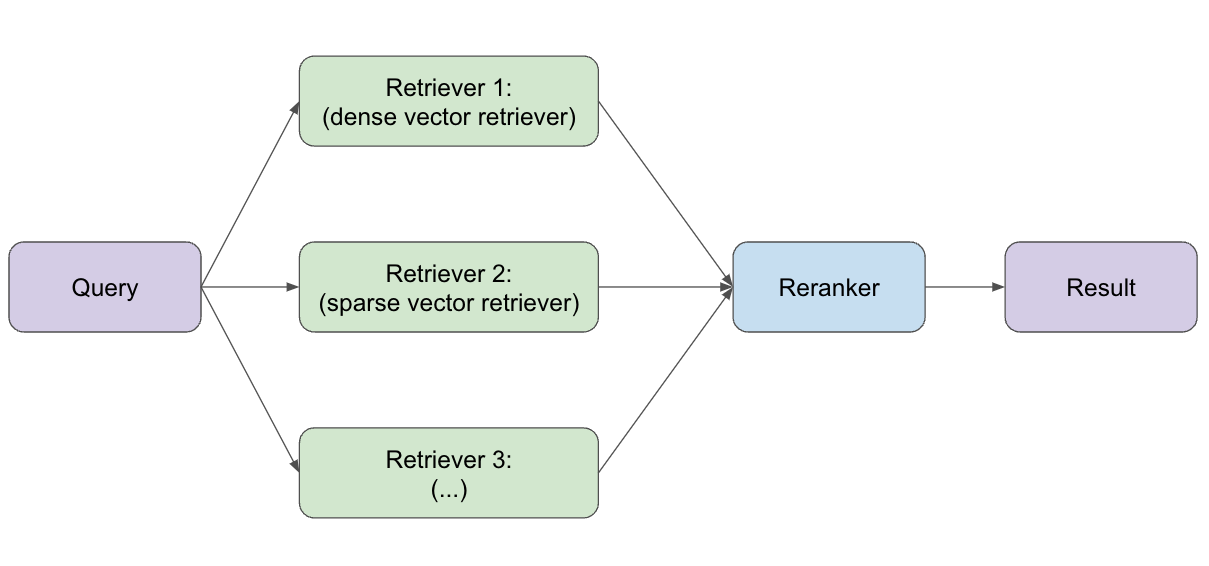
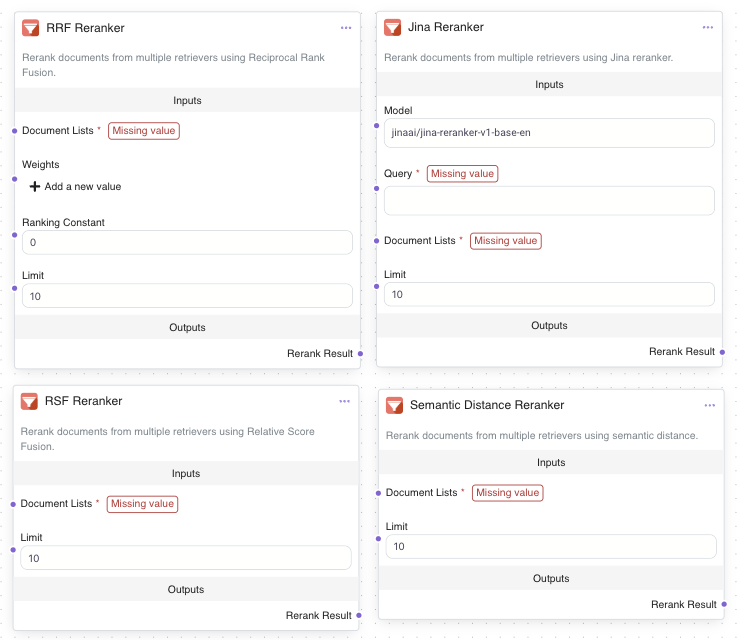
3. Reranking Methods Supported in Epsilla: The Key to Smarter Results
At Epsilla, we offer a variety of reranking methods to improve your search results. Each method focuses on different factors to help find the most relevant documents. These methods work together to ensure that the best results are always on top, giving you a smoother search experience.
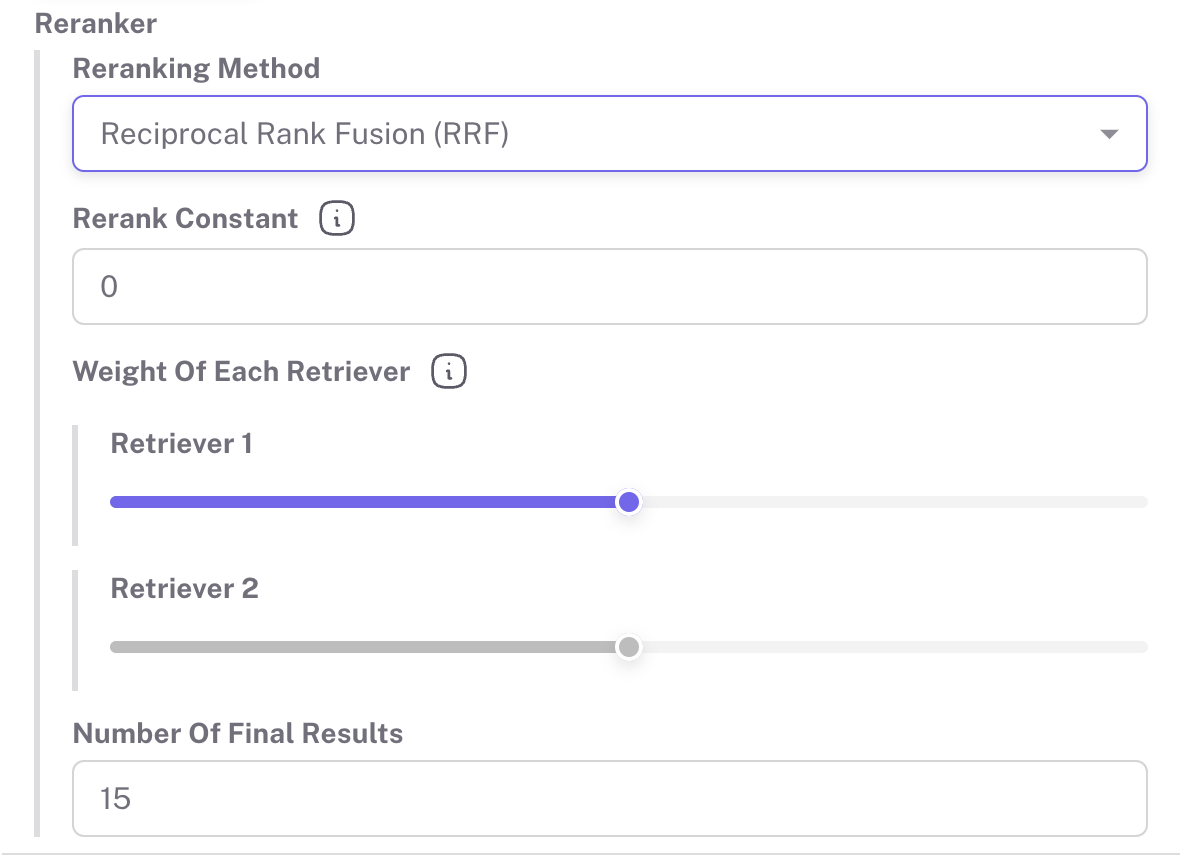
Reciprocal Rank Fusion (RRF)
Reciprocal Rank Fusion (RRF) gathers results from different retrievers and picks the best documents that show up at the top of multiple lists. The idea is simple: if a document ranks well in more than one list, it’s probably important. Here’s how it works:
Formula for RRF:
- score = 0.0 for i, retriever in retrievers: if doc in retriever.results: score += weights[i] / ( k + rank( retriever.results, doc ) ) return score
In this formula:
- weights[i] is the weight given to each retriever.
- k is a constant (usually set to 50).
- rank(retriever.results, doc) is the position of the document in a retriever’s list.
Documents that do well in many retrievers will get higher scores, making sure that only the most relevant ones come out on top.
API for RRF:
- search_engine.set_reranker( type="rrf", # or "reciprocal_rank_fusion" weights=[0.3, 0.7], # (Optional) give a weight for different retrivers, will use [1, 1, ...] if not provided k=50, # (Optional) ranking constant, default to 50 if not provided. limit=3, # (Optional) limit the top K results after reranking. If not provided, all documents from all retrievers will be returned )
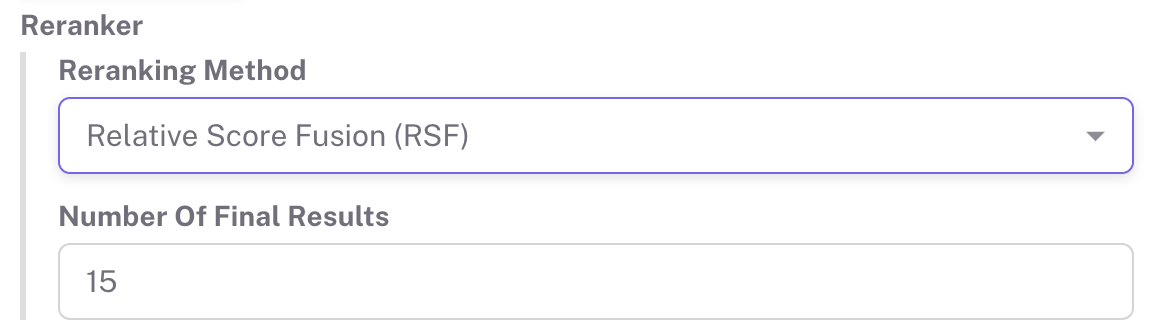
Relative Score Fusion (RSF)
Relative Score Fusion (RSF) is designed to improve search ranking by calculating the relative scores of documents across multiple retrievers and then reranking them based on these weighted scores. In simple terms, RSF ensures that the most relevant documents surface higher in the final ranking. Here’s how it works:
- First, RSF normalizes the scores from each retriever so that they are between 0 and 1.
- Then, it adds these scores together to get a total for each document.
- Documents with higher total scores are more relevant and appear first.
RSF helps to make sure the most relevant documents show up on top by using the combined scores from all retrievers.
API for RSF:
- search_engine.set_reranker( type="rsf", # or "relative_score_fusion" limit=3, # (Optional) limit the top K results after reranking. If not provided, all documents from all retrievers will be returned )
Distribution-Based Score Fusion (DBSF)
Distribution-Based Score Fusion (DBSF) takes RSF a step further by considering the distribution of scores from different retrievers. Rather than just normalizing scores, it normalizes the scores within a defined range, usually using the three-sigma rule. This ensures that the scores from different embedding models are consistent and comparable. Here’s what happens:
- The system adjusts the scores within a defined scale range, ensuring fairer comparisons across different types of embeddings.
- DBSF helps account for the differences in how retrievers score documents, making the ranking process more consistent and accurate.
API for DBSF:
- search_engine.set_reranker( type="dbsf", # or "distribution_based_score_fusion" scale_ranges=[ # Provide the scale range for each retriever based on the embedding model used [0.4, 0.8], [0.18, 0.3] ], limit=3, # (Optional) limit the top K results after reranking. If not provided, all documents from all retrievers will be returned )
Transformer-Based Rerankers (e.g., Jina AI)
For even better results, Epsilla integrated with advanced models like the Jina AI Reranker. This model uses machine learning to reorder them more accurately. The Jina AI Reranker learns from data to improve its ranking over time. Here’s how it works:
- The model looks at the relationship between the query and the documents.
- By using pre-trained models, like jinaai/jina-reranker-v1-base-en, it applies machine learning to reorder documents in a smarter way.
This technique works great when you need deep context to better understand the relevance of a document. It goes beyond simple matching and ensures that documents are ranked more accurately.

4. Reranker on Epsilla Workflow
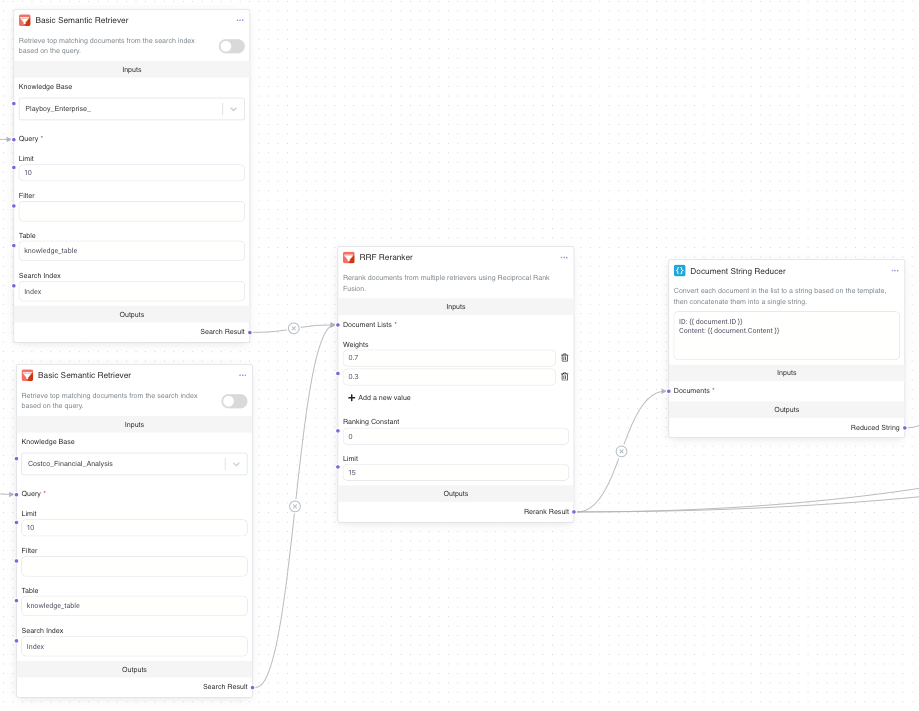
Epsilla’s platform offers a seamless workflow for managing your search and reranking tasks. With a no-code drag-and-drop interface, you can easily apply different rerankers in your agent workflow to best suit your needs.
In agent workflow, you can simply drag and drop components to add the rerankers you need. You can view and manage all components directly in the workflow, making it simple to adjust and fine-tune the ranking methods to improve the relevance of your search results.
Ready to supercharge your AI Agents? Start using Epsilla’s reranking methods today and experience faster, more relevant search outcomes every time. 👉 www.epsilla.com