
In our previous blog, we explored how Retrieval-Augmented Generation (RAG) enhances AI’s accuracy by combining large language models (LLMs) with real-time access to external knowledge bases. This two-step process — retrieving relevant data and generating enriched responses — bridges the gap between static model knowledge and up-to-date information.
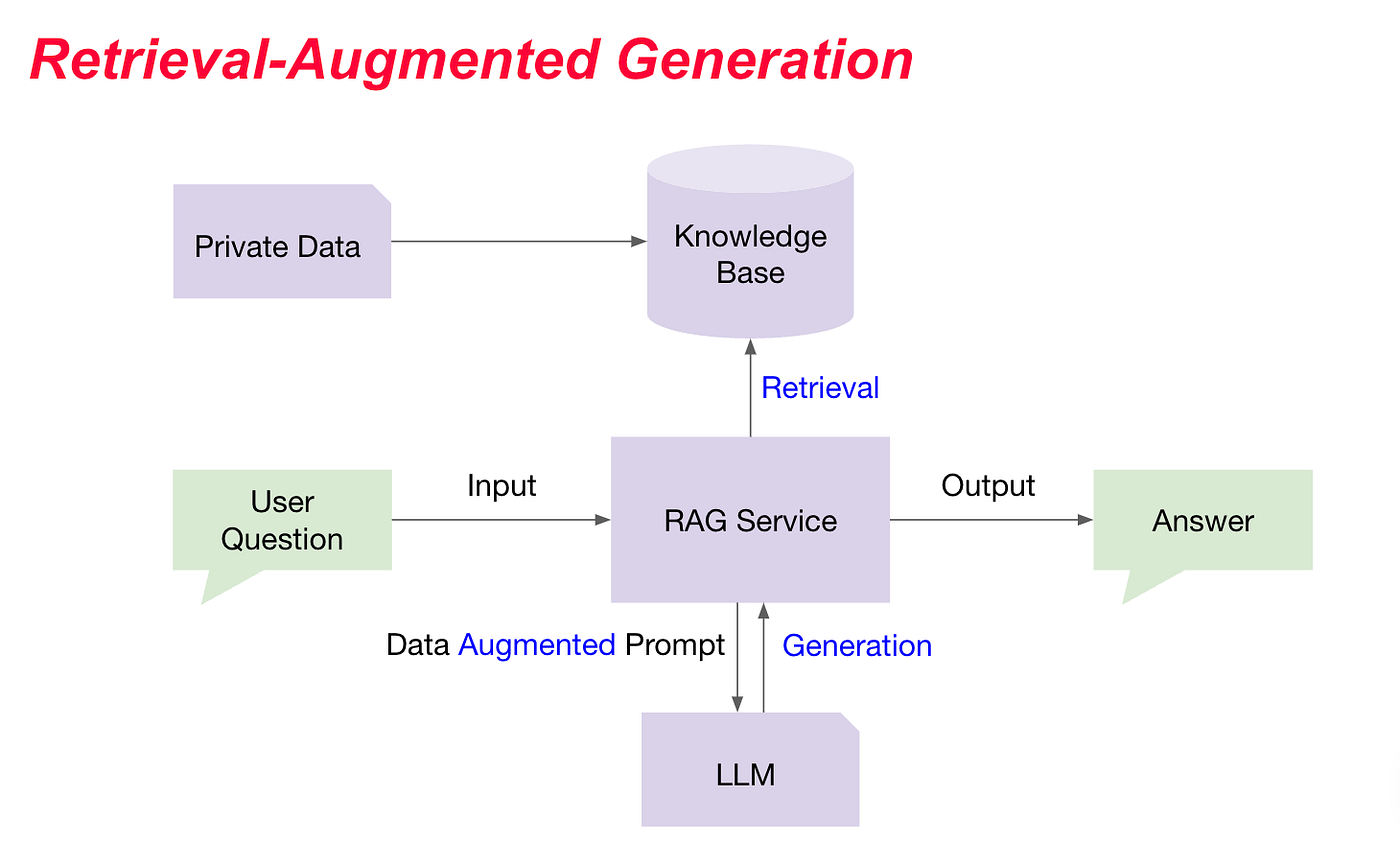
While RAG has already made AI responses more reliable by connecting language models with real-time data retrieval, it has its limitations, especially with complex or ambiguous questions. Traditional RAG systems retrieve information based on a single interpretation of a user’s query, which can sometimes lead to incomplete or less relevant answers. As user questions become more nuanced, there’s a need for an approach that can capture multiple perspectives and deliver even greater accuracy. This is where RAG Fusion comes in, taking RAG’s capabilities a step further by enhancing its retrieval and ranking methods to provide responses that are truly aligned with user intent, even for intricate queries.
Introducing RAG Fusion
So, what sets RAG Fusion apart, and how does it enhance the capabilities of traditional RAG?
The Evolution to RAG Fusion
RAG Fusion builds upon the foundation of RAG by refining the retrieval process to capture the nuances of human queries more effectively. It’s designed to handle complex, ambiguous, or less-than-perfectly-worded questions, making AI interactions more intuitive and helpful.
How RAG Fusion Works

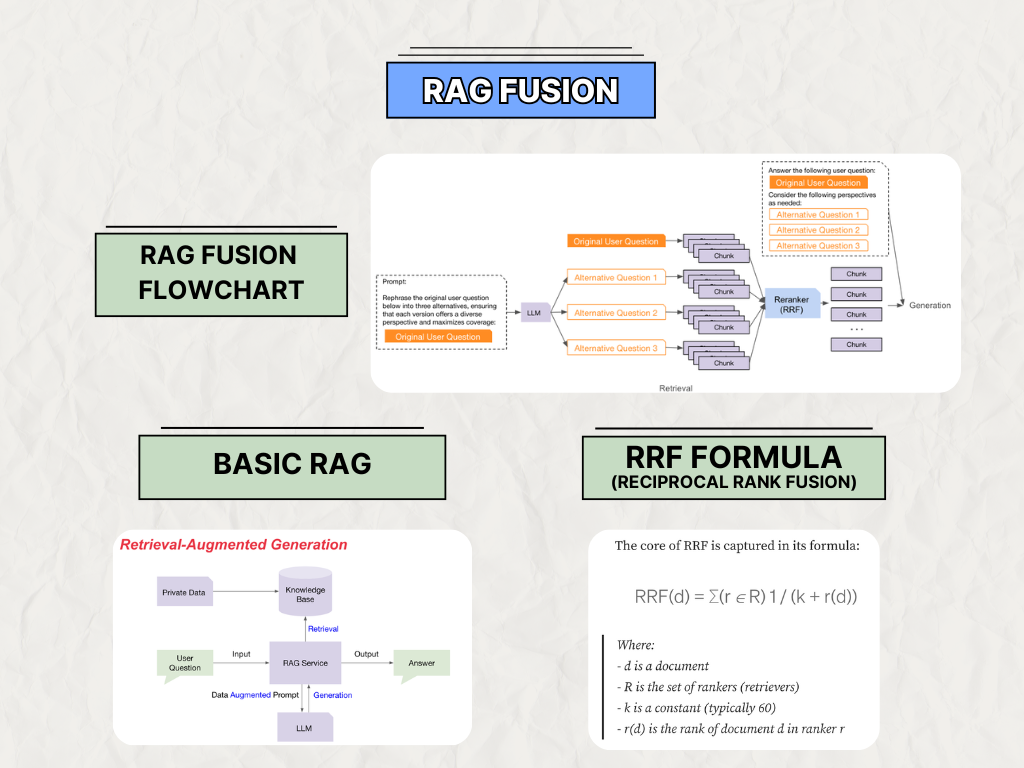
The core idea behind RAG Fusion addresses a common challenge in AI: users often phrase their questions vaguely or without sufficient detail, making it difficult for an AI to accurately understand their intent. RAG Fusion tackles this by using a large language model to “rephrase” the original question, generating several alternative versions or perspectives of the user’s query. These alternative questions, each capturing a different possible interpretation, are then processed together with the original question.
Once the original and alternative questions are prepared, RAG Fusion conducts a retrieval step for each one, pulling relevant information from the knowledge base. This approach ensures that a diverse set of documents, or “chunks,” is retrieved, covering multiple facets of the user’s query. The retrieved documents from both the original and alternative questions are then consolidated through a reranking mechanism called Reciprocal Rank Fusion (RRF). This reranker combines the results into a single, prioritized list, ensuring that the most relevant information across all variations is brought together.
Finally, this curated list of information is passed to the generation phase, where the AI synthesizes the consolidated insights to produce a comprehensive, contextually rich response. By combining multiple perspectives in this way, RAG Fusion delivers answers that are more accurate and nuanced, even when the original question is ambiguous or underspecified.
A Closer Look at Reranking with Reciprocal Rank Fusion (RRF)
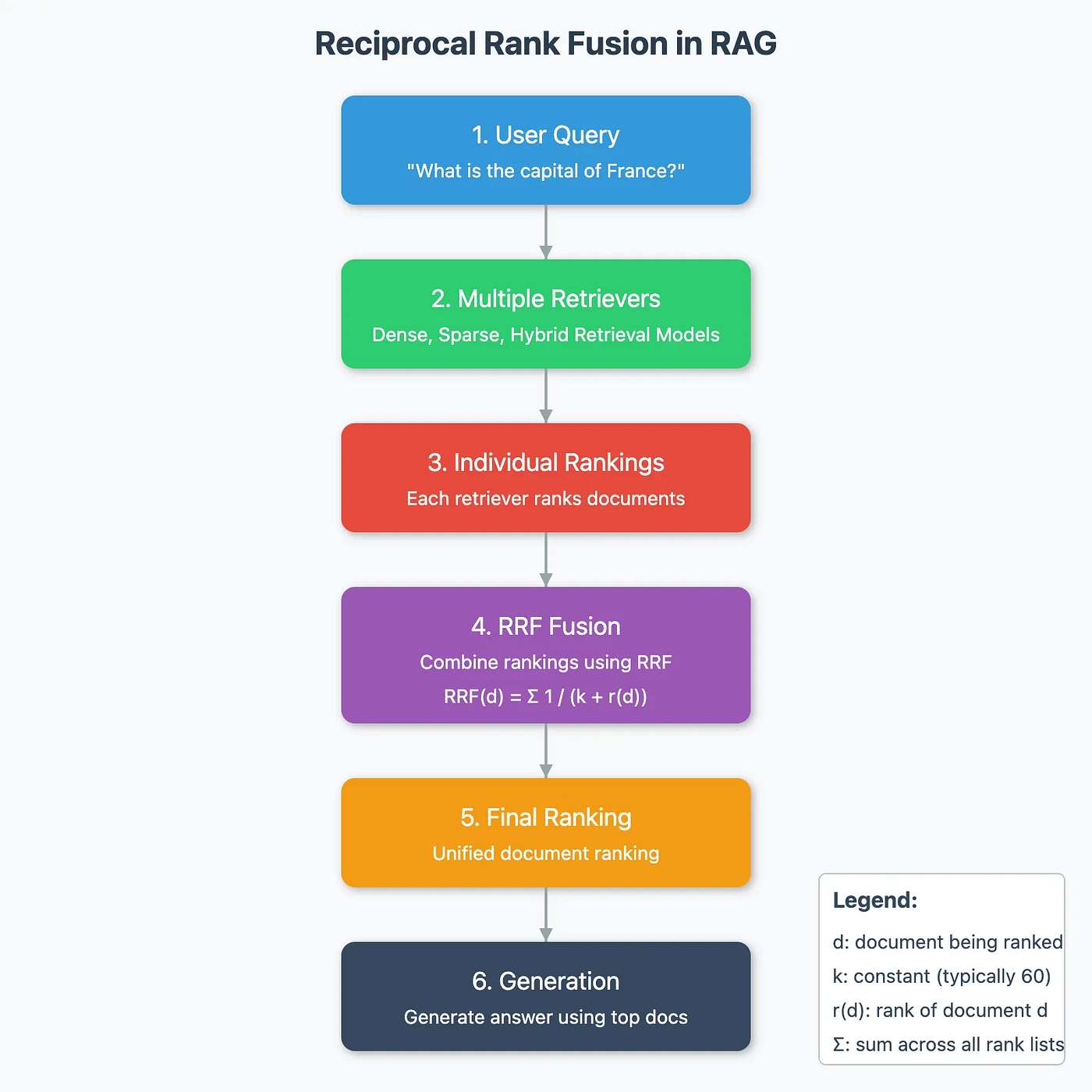
In RAG Fusion, Reciprocal Rank Fusion (RRF) is employed as a heuristic reranking method to combine and prioritize the results retrieved from different query variations, including the original question and its rephrased alternatives. This approach addresses the challenge of consolidating multiple lists of documents, each retrieved based on a different perspective of the user’s query. The idea behind RRF is simple but effective: documents that consistently rank higher across multiple lists are given more weight in the final ranking. If a document appears near the top in several lists, it is likely to be highly relevant to the original query.
The RRF Formula

This formula ensures that documents ranked near the top in individual lists contribute more significantly to the final ranking, as a smaller rank value results in a higher score due to the smaller denominator. For example, if a document ranks first in a list, it will receive a larger score boost compared to documents ranked lower.
RRF also allows for adjustable weights based on the relevance of each query version. For instance, the original question might carry a higher weight (e.g., 0.4), while alternative queries are assigned smaller weights (e.g., 0.2 each). This gives greater influence to results that are directly relevant to the original query while still considering insights from alternative perspectives.

By aggregating these weighted scores across all lists, RRF produces a consolidated ranking that prioritizes the most relevant documents. This reranked list is then passed to the generation phase, where the AI uses it to craft a response that is both comprehensive and accurately aligned with the user’s intent. In this way, RRF enhances RAG Fusion’s ability to interpret and respond to complex or ambiguous queries effectively.

Implementing RAG Fusion on Epsilla
In this section, we’ll walk through how RAG Fusion is configured and executed within Epsilla’s agent workflow editor, showcasing each step in detail. Epsilla’s platform provides a structured and adaptable environment for deploying RAG Fusion, allowing users to enhance the accuracy and depth of AI responses by leveraging advanced retrieval and reranking techniques. From breaking down the user’s initial question to prioritizing information with Reciprocal Rank Fusion, we’ll demonstrate the entire process with visual guides and step-by-step descriptions. The best part? You don’t need to write a single line of code!
Step 1: Decomposing the User Question with LLM Node
In the first step, a Large Language Model (LLM) Node is added to the workflow. This node rephrases the original user question into three alternative versions, each crafted to cover a unique perspective of the question. This decomposition is crucial, as it ensures that different angles of the query are addressed, enhancing the depth of the final response.
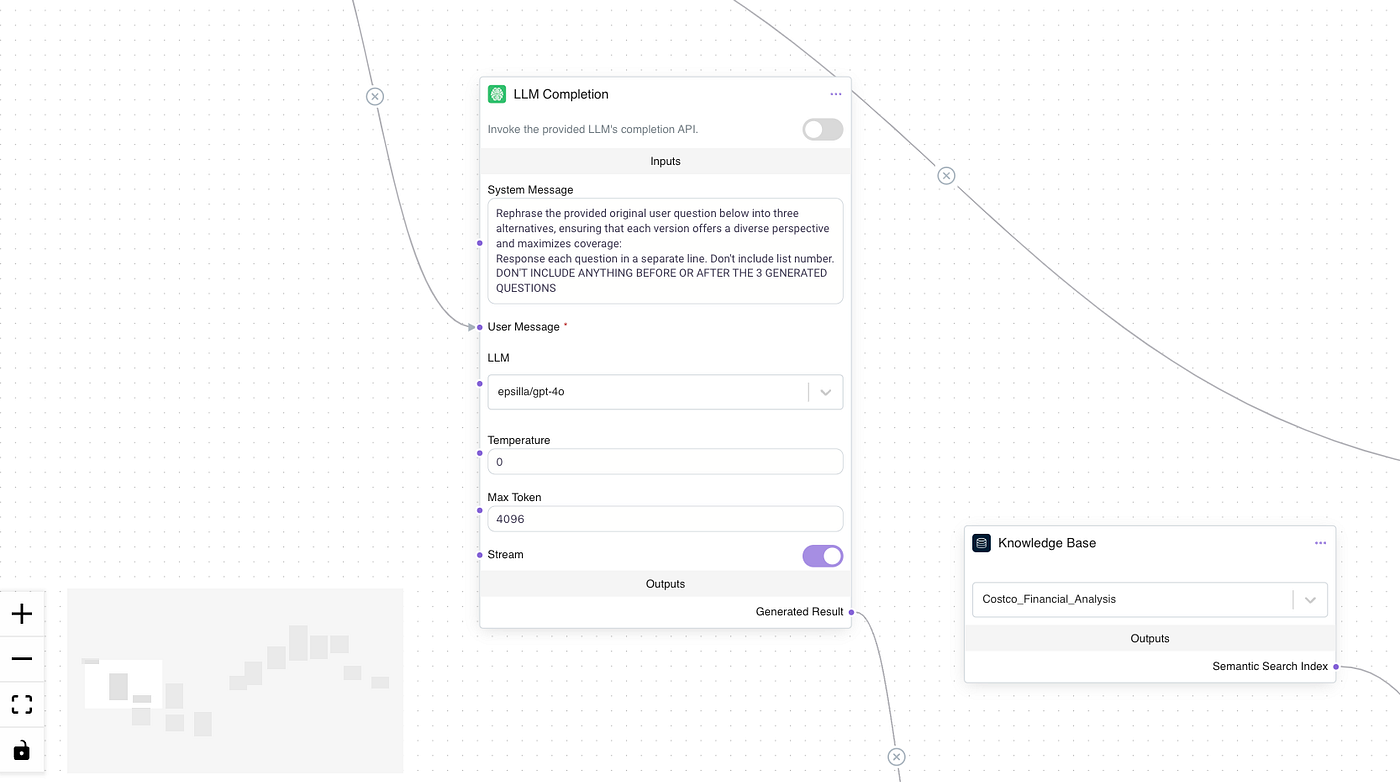
Step 2: Compiling the List of Questions (String Split Node)
Once the LLM has generated alternative questions, a String Split Node is used to organize these into a list. This list now includes the original question and its three alternatives. Each question in this list will undergo an independent retrieval process, allowing the system to gather information from various perspectives.
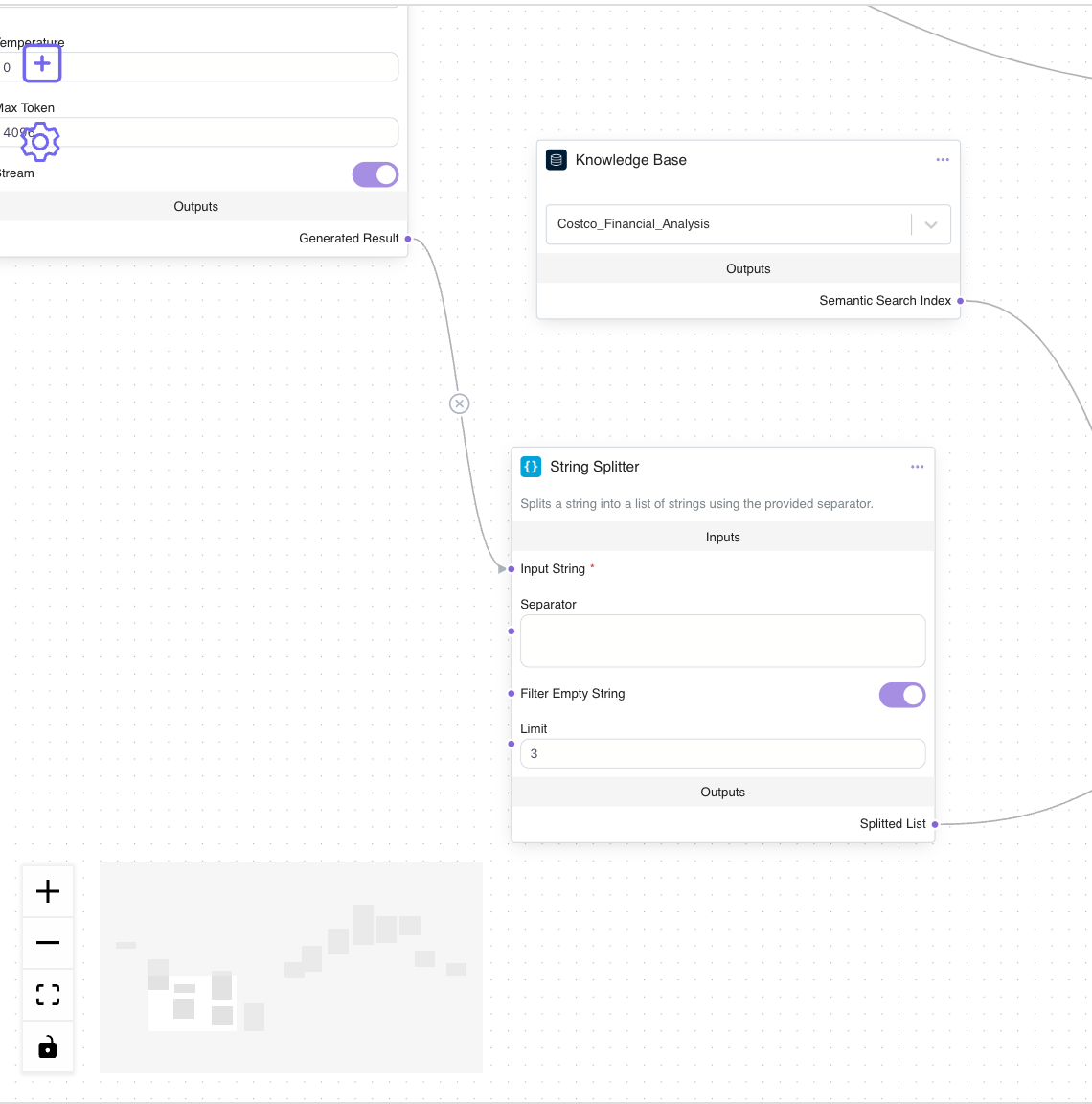
Step 3: Semantic Retrieval with Batch Basic Retriever Node
In this step, a Batch Basic Retriever Node is added to the workflow. This node takes the list of questions and performs a semantic retrieval from the designated knowledge base. By leveraging a batch retrieval function, this node processes all query variations simultaneously, ensuring each version retrieves a unique set of documents. The retrieval results provide “chunks” of relevant information tailored to each interpretation of the original query.
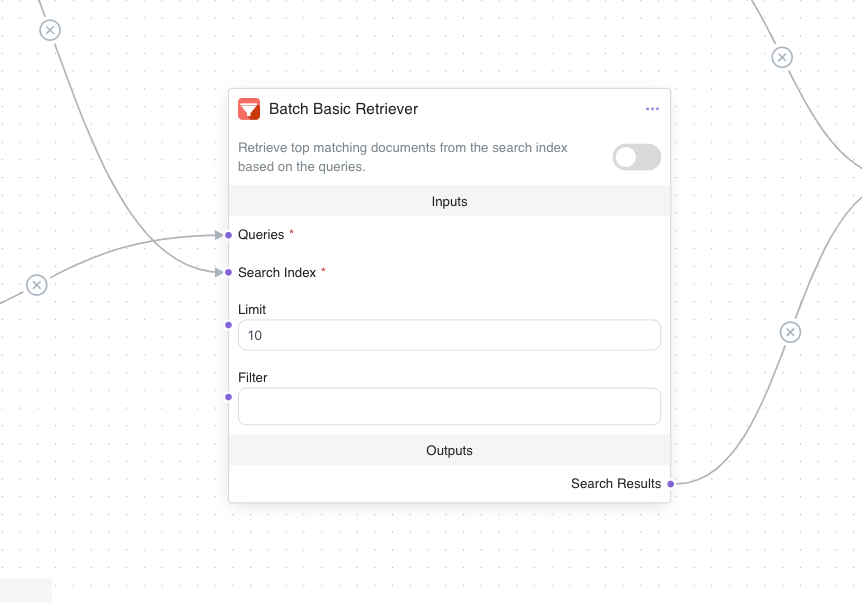
Step 4: Reranking with Reciprocal Rank Fusion (RRF) Node
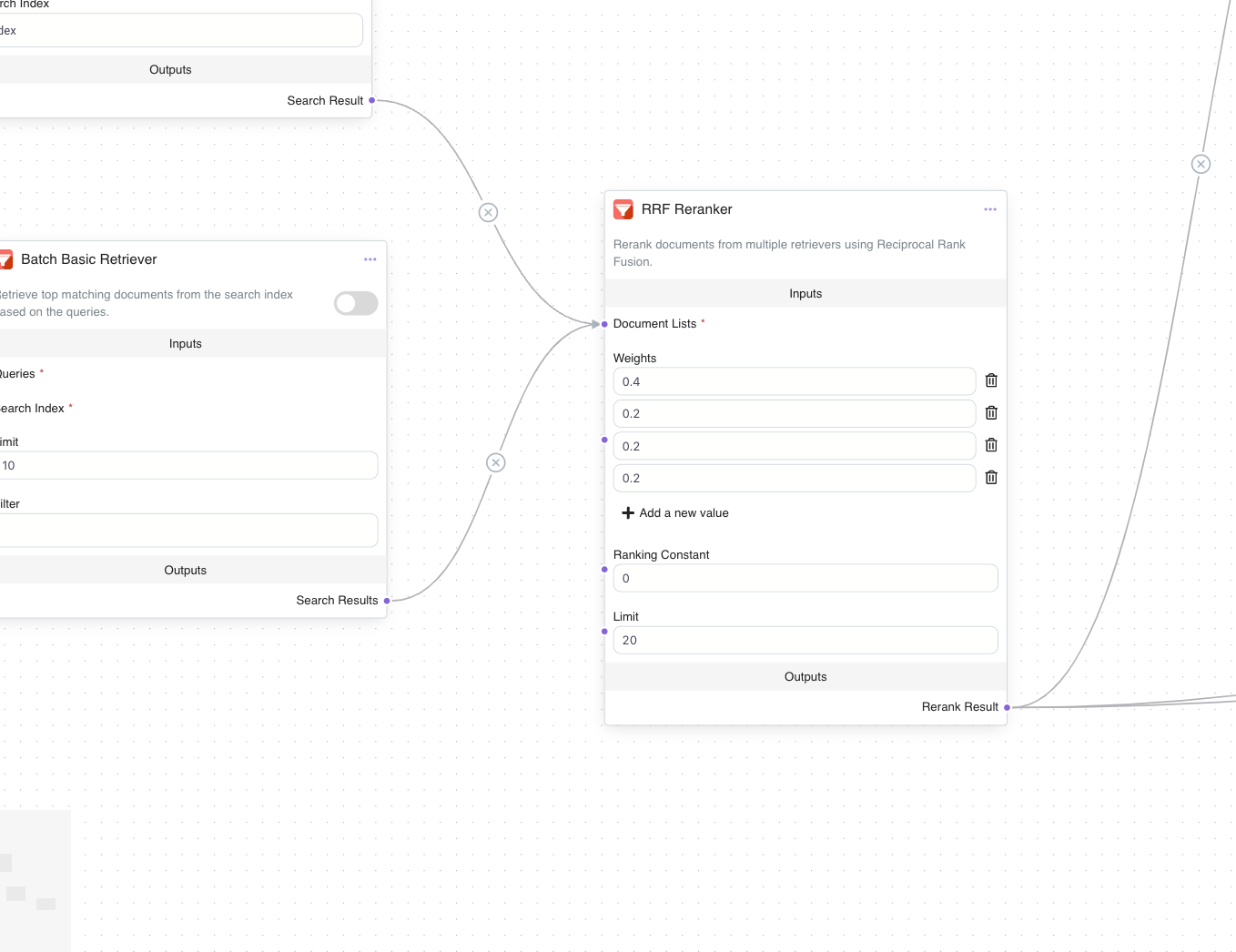
After retrieval, an RRF Reranker Node is introduced to rerank and consolidate the documents. This node applies the Reciprocal Rank Fusion (RRF) formula, prioritizing documents that appear consistently across multiple question variants. The reranker takes into account each document’s ranking position across different lists and combines them into a single prioritized list, with higher weight given to documents from the original question.
Step 5: Generating the Final Response with Generation Node
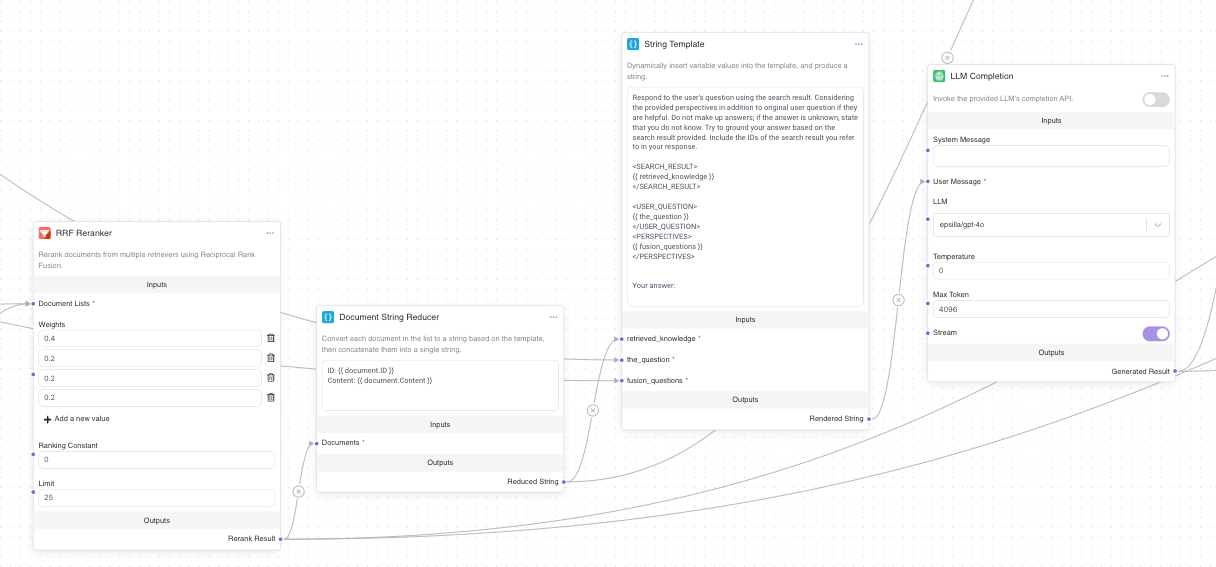
Lastly, let’s connect the RRF Node with the LLM Completion node via Document String Reducer (converts document objects into a string) and String Template (renders the final prompt string). The LLM Completion node uses the consolidated information from the reranked list and generates a response that is accurate, contextually relevant, and aligned with the user’s original intent. By drawing on information gathered through the RAG Fusion process, this final response covers multiple perspectives, ensuring a comprehensive answer.
Scenario: Costco Financial Analysis
To illustrate the impact of RAG Fusion on response quality, let’s look at a real-world example involving a financial analysis question about Costco. In a side-by-side comparison of AI-generated responses, we can see that the answer produced through RAG Fusion is notably more detailed and logically structured.
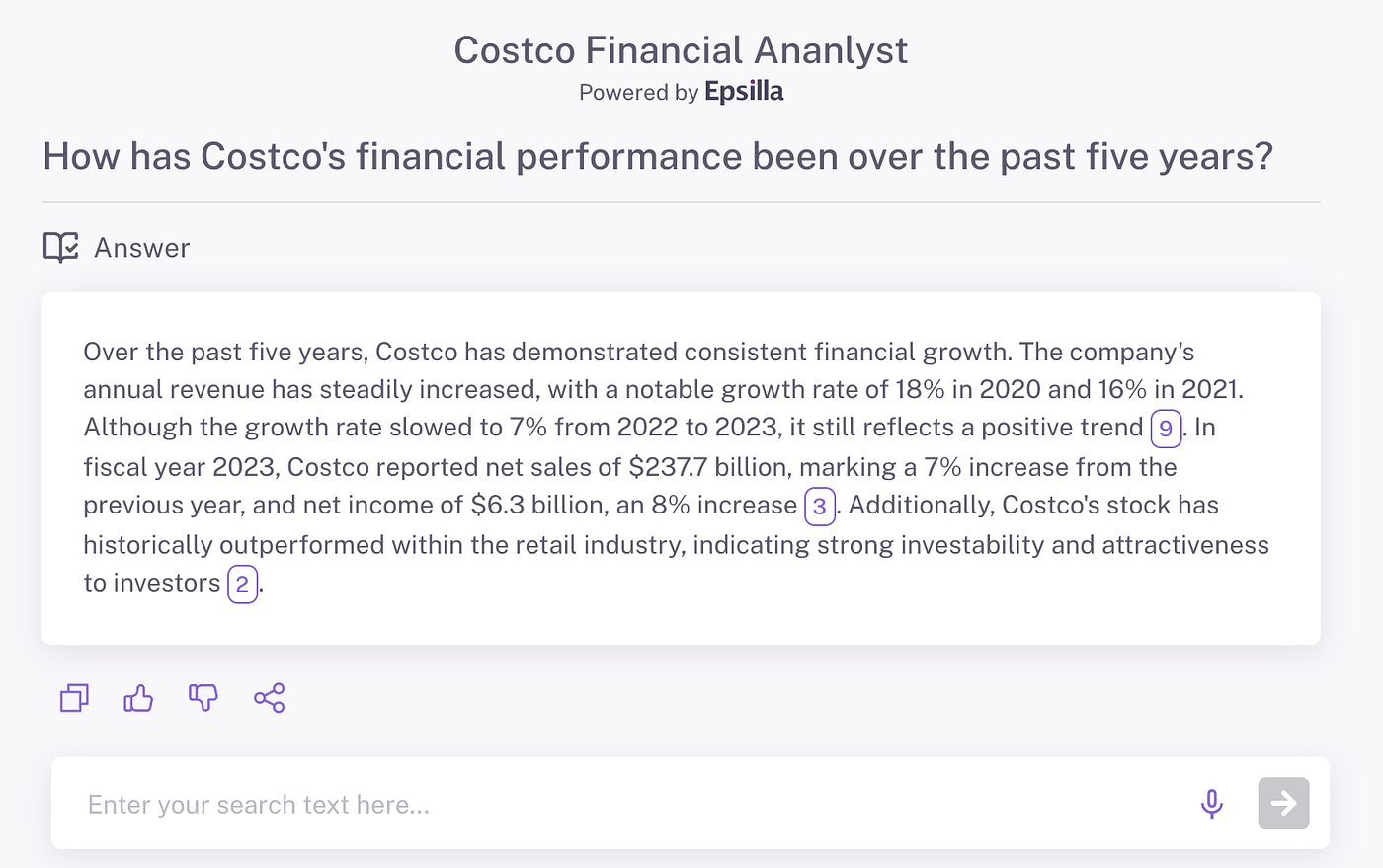
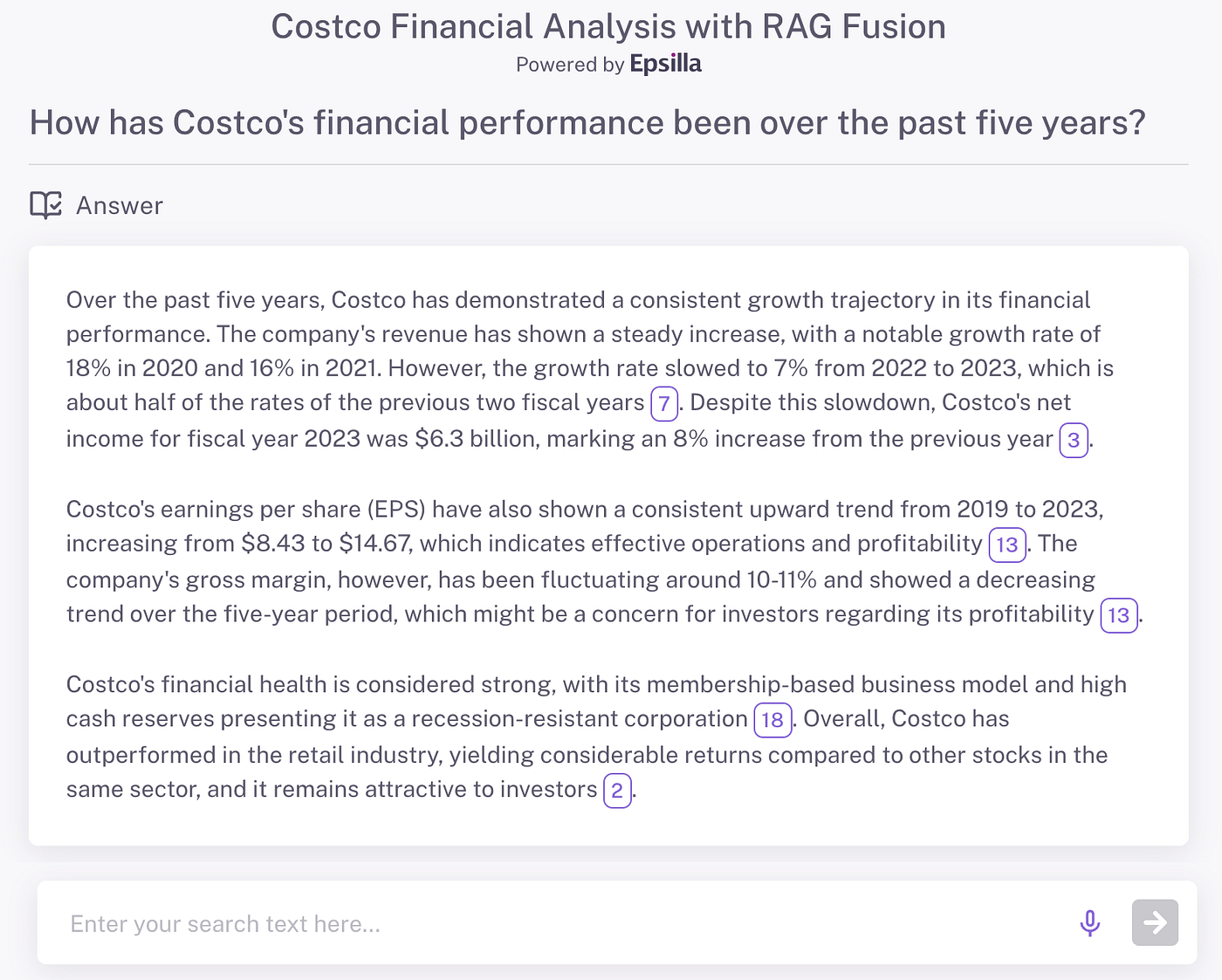
As a result, the RAG Fusion-generated response for the Costco analysis is comprehensive, covering both the financial metrics and contextual insights that make for a more logically structured answer. By comparison, a traditional RAG setup might overlook some of these critical details, resulting in a response that is less thorough and organized.
Conclusion: Elevating AI with RAG Fusion on Epsilla
As we’ve explored, RAG Fusion represents a powerful advancement in AI’s ability to deliver accurate, context-aware answers to complex queries. By combining retrieval from multiple perspectives, sophisticated reranking through Reciprocal Rank Fusion, and structured generation, RAG Fusion overcomes some of the key limitations of traditional retrieval-augmented generation models. In Epsilla, each step in this process — from decomposing the user’s question into diverse alternatives to generating a unified, prioritized response — enhances the depth, accuracy, and coherence of AI-generated answers.
The example we examined with Costco’s financial analysis shows RAG Fusion’s capacity for detail and logical organization. Compared to standard retrieval methods, the RAG Fusion approach in Epsilla yields answers that are not only richer in content but also aligned with the nuances of user intent. This method proves especially valuable in professional contexts where accuracy and insight are paramount.
Looking Ahead
As AI technology continues to evolve, so too does the need for more flexible, intelligent retrieval methods like RAG Fusion. Whether you’re an AI developer, a data analyst, or simply curious about the next wave of intelligent systems, RAG Fusion offers exciting possibilities. With Epsilla, implementing this advanced workflow becomes a practical reality, opening doors to more responsive, insightful, and user-centered applications.
Ready to see RAG Fusion in action? Discover into Epsilla’s platform now, experiment with the workflow, and explore how this advanced AI technique can elevate your projects to new levels. Let’s push the boundaries of what AI can achieve — one well-crafted question at a time.